
Textual Analysis for Network Attack Recognition
Application to Real Data
Applying Textual Analysis to Detect Patterns in Logs
Here are some preliminary results for applying these textual analysis techniques to log data.
Somewhat surprisingly, with English prose the measures of resemblance, containment, and Dice's coefficient were of little use but the vector space model worked reasonably well.
The opposite is true with the syslog data. The vector space model was of little use, its results are not shown here.
| Set | Number of 7-Shingles |
Attacker | Target |
| A | 316 | 136.199.196.40 | c193 |
| B | 19 | 136.199.196.40 | i192 |
| C | 258 | 136.199.196.40 | x053 |
| D | 162 | 194.204.212.6 | x053 |
| E | 400 | 200.32.73.4 | c193 |
| F | 826 | 200.32.73.4 | i192 |
| G | 207 | 200.32.73.4 | x053 |
| H | 62 | 202.131.2.167 | i192 |
| I | 17 | 202.131.2.167 | x053 |
| J | 3042 | 211.96.64.124 | c193 |
| K | 3042 | 211.96.64.124 | i192 |
| L | 1088 | 211.96.64.124 | x053 |
| M | 902 | 217.9.0.196 | c193 |
| N | 9391 | 217.9.0.196 | i192 |
| O | 76 | 217.9.0.196 | x053 |
A collection of log data was selected, including 15 attack sequences from 6 attacking hosts.
Below are the results of the resemblance measure. The following sets of attack sequences are each from the same attacking host, where sequences J and K are identical:
- A, B, C
- D
- E, F, G
- H, I
- J, K, L
- M, N, O
Picking an arbitrary threshold of 0.3, the values colored in green in the following tables show correct classification of similar attack form, while values in yellow show errors — within-source measures below the cutoff (false-negative error) or between-source measures above it (false-positive error).
Resemblance table:
A B C D E F G H I J K L M N O
A 1.00000 0.06485 0.80205 0.00000 0.00296 0.00193 0.00203 0.00000 0.00000 0.00066 0.00066 0.00161 0.00152 0.00030 0.00000
B 0.06485 1.00000 0.08085 0.00000 0.00248 0.00131 0.00459 0.00000 0.00000 0.00036 0.00036 0.00103 0.00260 0.00015 0.00000
C 0.80205 0.08085 1.00000 0.00000 0.00324 0.00205 0.00230 0.00000 0.00000 0.00067 0.00067 0.00168 0.00167 0.00030 0.00000
D 0.00000 0.00000 0.00000 1.00000 0.03795 0.02257 0.05848 0.37423 0.09816 0.05925 0.05925 0.16963 0.00000 0.01469 0.00000
E 0.00296 0.00248 0.00324 0.03795 1.00000 0.51747 0.51948 0.02288 0.00000 0.01299 0.01299 0.02056 0.00133 0.00175 0.00000
F 0.00193 0.00131 0.00205 0.02257 0.51747 1.00000 0.26882 0.01256 0.00000 0.12230 0.12230 0.17741 0.00090 0.00181 0.00000
G 0.00203 0.00459 0.00230 0.05848 0.51948 0.26882 1.00000 0.03968 0.00000 0.01172 0.01172 0.01852 0.00177 0.00165 0.00000
H 0.00000 0.00000 0.00000 0.37423 0.02288 0.01256 0.03968 1.00000 0.27419 0.02230 0.02230 0.06381 0.00000 0.00431 0.00000
I 0.00000 0.00000 0.00000 0.09816 0.00000 0.00000 0.00000 0.27419 1.00000 0.00585 0.00585 0.01674 0.00000 0.00247 0.00000
J 0.00066 0.00036 0.00067 0.05925 0.01299 0.12230 0.01172 0.02230 0.00585 1.00000 1.00000 0.34931 0.00032 0.01121 0.00000
K 0.00066 0.00036 0.00067 0.05925 0.01299 0.12230 0.01172 0.02230 0.00585 1.00000 1.00000 0.34931 0.00032 0.01121 0.00000
L 0.00161 0.00103 0.00168 0.16963 0.02056 0.17741 0.01852 0.06381 0.01674 0.34931 0.34931 1.00000 0.00076 0.01393 0.00000
M 0.00152 0.00260 0.00167 0.00000 0.00133 0.00090 0.00177 0.00000 0.00000 0.00032 0.00032 0.00076 1.00000 0.05658 0.20765
N 0.00030 0.00015 0.00030 0.01469 0.00175 0.00181 0.00165 0.00431 0.00247 0.01121 0.01121 0.01393 0.05658 1.00000 0.01175
O 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.20765 0.01175 1.00000
Containment table:
A B C D E F G H I J K L M N O
A 1.00000 1.00000 1.00000 0.00000 0.00520 0.00269 0.00500 0.00000 0.00000 0.00073 0.00073 0.00209 0.00273 0.00031 0.00000
B 0.06485 1.00000 0.08085 0.00000 0.00260 0.00134 0.00500 0.00000 0.00000 0.00037 0.00037 0.00105 0.00273 0.00016 0.00000
C 0.80205 1.00000 1.00000 0.00000 0.00520 0.00269 0.00500 0.00000 0.00000 0.00073 0.00073 0.00209 0.00273 0.00031 0.00000
D 0.00000 0.00000 0.00000 1.00000 0.05195 0.02688 0.10000 0.98387 0.94118 0.05925 0.05925 0.16963 0.00000 0.01484 0.00000
E 0.00683 0.05263 0.00851 0.12346 1.00000 0.51747 1.00000 0.16129 0.00000 0.01463 0.01463 0.02827 0.00273 0.00186 0.00000
F 0.00683 0.05263 0.00851 0.12346 1.00000 1.00000 1.00000 0.16129 0.00000 0.13863 0.13863 0.26806 0.00273 0.00201 0.00000
G 0.00341 0.05263 0.00426 0.12346 0.51948 0.26882 1.00000 0.16129 0.00000 0.01244 0.01244 0.02199 0.00273 0.00170 0.00000
H 0.00000 0.00000 0.00000 0.37654 0.02597 0.01344 0.05000 1.00000 1.00000 0.02231 0.02231 0.06387 0.00000 0.00433 0.00000
I 0.00000 0.00000 0.00000 0.09877 0.00000 0.00000 0.00000 0.27419 1.00000 0.00585 0.00585 0.01675 0.00000 0.00247 0.00000
J 0.00683 0.05263 0.00851 1.00000 0.10390 0.50941 0.17000 0.98387 0.94118 1.00000 1.00000 1.00000 0.00273 0.01577 0.00000
K 0.00683 0.05263 0.00851 1.00000 0.10390 0.50941 0.17000 0.98387 0.94118 1.00000 1.00000 1.00000 0.00273 0.01577 0.00000
L 0.00683 0.05263 0.00851 1.00000 0.07013 0.34409 0.10500 0.98387 0.94118 0.34931 0.34931 1.00000 0.00273 0.01577 0.00000
M 0.00341 0.05263 0.00426 0.00000 0.00260 0.00134 0.00500 0.00000 0.00000 0.00037 0.00037 0.00105 1.00000 0.05658 1.00000
N 0.00683 0.05263 0.00851 0.59259 0.03117 0.01747 0.05500 0.45161 0.94118 0.03731 0.03731 0.10681 1.00000 1.00000 1.00000
O 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.20765 0.01175 1.00000
Dice's coefficient table:
A B C D E F G H I J K L M N O
A 1.00000 0.12180 0.89015 0.00000 0.00590 0.00386 0.00406 0.00000 0.00000 0.00132 0.00132 0.00321 0.00304 0.00059 0.00000
B 0.12180 1.00000 0.14961 0.00000 0.00495 0.00262 0.00913 0.00000 0.00000 0.00073 0.00073 0.00205 0.00520 0.00031 0.00000
C 0.89015 0.14961 1.00000 0.00000 0.00645 0.00409 0.00460 0.00000 0.00000 0.00135 0.00135 0.00336 0.00333 0.00060 0.00000
D 0.00000 0.00000 0.00000 1.00000 0.07313 0.04415 0.11050 0.54464 0.17877 0.11188 0.11188 0.29006 0.00000 0.02896 0.00000
E 0.00590 0.00495 0.00645 0.07313 1.00000 0.68202 0.68376 0.04474 0.00000 0.02565 0.02565 0.04030 0.00266 0.00350 0.00000
F 0.00386 0.00262 0.00409 0.04415 0.68202 1.00000 0.42373 0.02481 0.00000 0.21794 0.21794 0.30135 0.00180 0.00361 0.00000
G 0.00406 0.00913 0.00460 0.11050 0.68376 0.42373 1.00000 0.07634 0.00000 0.02318 0.02318 0.03636 0.00353 0.00330 0.00000
H 0.00000 0.00000 0.00000 0.54464 0.04474 0.02481 0.07634 1.00000 0.43038 0.04363 0.04363 0.11996 0.00000 0.00857 0.00000
I 0.00000 0.00000 0.00000 0.17877 0.00000 0.00000 0.00000 0.43038 1.00000 0.01163 0.01163 0.03292 0.00000 0.00493 0.00000
J 0.00132 0.00073 0.00135 0.11188 0.02565 0.21794 0.02318 0.04363 0.01163 1.00000 1.00000 0.51776 0.00064 0.02217 0.00000
K 0.00132 0.00073 0.00135 0.11188 0.02565 0.21794 0.02318 0.04363 0.01163 1.00000 1.00000 0.51776 0.00065 0.02217 0.00000
L 0.00321 0.00205 0.00336 0.29006 0.04030 0.30135 0.03636 0.11996 0.03292 0.51776 0.51776 1.00000 0.00151 0.02748 0.00000
M 0.00304 0.00520 0.00333 0.00000 0.00266 0.00180 0.00353 0.00000 0.00000 0.00064 0.00065 0.00151 1.00000 0.10710 0.34389
N 0.00059 0.00031 0.00060 0.02896 0.00350 0.00361 0.00330 0.00857 0.00493 0.02217 0.02217 0.02748 0.10710 1.00000 0.02322
O 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.34389 0.02322 1.00000
Discussion of the Results
Resemblance and Dice's coefficient seem most useful. Dice's coefficient performed slightly better on this data set.
The containment measure was less useful due to false-positive matches, as might be expected. Small sequences (e.g., H and I) are contained within large sequences (D, J, K, L, and N in this case).
Set: H I D J K L N
Shingles: 62 17 162 3042 3042 1088 9391
Classification was better on sets of similar sizes than on sets where one sequence terminated much earlier. Again, this makes sense:
Better: Set: E F G
Shingles: 400 826 207
Set: H I
Shingles: 62 17
Set: J K L
Shingles: 3042 3042 1088
Worse: Set: A B C
Shingles: 316 19 258
Set: M N O
Shingles: 902 9391 76
Looking just at resemblance and Dice's coefficient, we can first rule out those measures not of interest:
- Values on the diagonal.
- Values below the diagonal, as the tables are symmetric.
- Measures between identical sequences J and K.
So, the eleven true positive matches of interest are:
AB, AC, BC,
EF, EG, FG,
HI,
JL,
MN, MO, NO
and the true negative matches of interest are the remaining
80 pairs.
The thresholds could be adjusted to optimize the error rates for the resemblance and Dice's coefficient classification. Study of the tables shows the following performances with varying thresholds. The maximum total correct classifications and the crossover points are highlighted.
Resemblance:
| Threshold | Total Correct | Matches correctly classified | Non-matches correctly classified |
| 0.80206 — 1.00000 | 80/91 88% | 0/11 0% | 80/80 100% |
| 0.51949 — 0.80204 | 81/91 89% | 1/11 9% | 80/80 100% |
| 0.51748 — 0.51947 | 82/91 90% | 2/11 18% | 80/80 100% |
| 0.37424 — 0.51746 | 83/91 91% | 3/11 27% | 80/80 100% |
| 0.34932 — 0.37422 | 82/91 90% | 3/11 27% | 79/80 99% |
| 0.27420 — 0.34930 | 83/91 91% | 4/11 36% | 79/80 99% |
| 0.26883 — 0.27418 | 84/91 92% | 5/11 45% | 79/80 99% |
| 0.20766 — 0.26881 | 85/91 93% | 6/11 55% | 79/80 99% |
| 0.17742 — 0.20764 | 86/91 95% | 7/11 64% | 79/80 99% |
| 0.16964 — 0.17740 | 85/91 93% | 7/11 64% | 78/80 98% |
| 0.12231 — 0.16962 | 84/91 92% | 7/11 64% | 77/80 96% |
| 0.09817 — 0.12233 | 83/91 91% | 7/11 64% | 76/80 95% |
| 0.08086 — 0.09815 | 82/91 90% | 7/11 64% | 75/80 94% |
| 0.06486 — 0.08084 | 83/91 91% | 8/11 73% | 75/80 94% |
| 0.06382 — 0.06484 | 84/91 92% | 9/11 82% | 75/80 94% |
| 0.05926 — 0.06380 | 83/91 91% | 9/11 82% | 74/80 93% |
| 0.05849 — 0.05924 | 82/91 90% | 9/11 82% | 73/80 91% |
| 0.05659 — 0.05847 | 81/91 89% | 9/11 82% | 72/80 90% |
| 0.03969 — 0.05657 | 82/91 90% | 10/11 91% | 72/80 90% |
| 0.03796 — 0.03967 | 81/91 89% | 10/11 91% | 71/80 89% |
| 0.02289 — 0.03794 | 80/91 88% | 10/11 91% | 70/80 88% |
| 0.02258 — 0.02287 | 79/91 87% | 10/11 91% | 69/80 86% |
| 0.02229 — 0.02256 | 78/91 86% | 10/11 91% | 68/80 85% |
| 0.02057 — 0.02231 | 77/91 85% | 10/11 91% | 67/80 84% |
| 0.01853 — 0.02231 | 76/91 84% | 10/11 91% | 66/80 83% |
| 0.01675 — 0.02231 | 75/91 82% | 10/11 91% | 65/80 81% |
| 0.01470 — 0.01673 | 74/91 81% | 10/11 91% | 64/80 80% |
| 0.01394 — 0.01468 | 73/91 80% | 10/11 91% | 63/80 79% |
| 0.01300 — 0.01392 | 72/91 79% | 10/11 91% | 62/80 78% |
| 0.01176 — 0.01298 | 71/91 78% | 10/11 91% | 61/80 76% |
| 0.01173 — 0.01174 | 72/91 79% | 11/11 100% | 61/80 76% |
| 0.00001 — 0.01171 | 65-71/91 71-78% | 11/11 100% | 54-60/80 68-75% |
Dice's Coefficient:
| Threshold | Total Correct | Matches correctly classified | Non-matches correctly classified |
| 0.89016 — 1.00000 | 80/91 88% | 0/11 0% | 80/80 100% |
| 0.68377 — 0.89016 | 81/91 89% | 1/11 9% | 80/80 100% |
| 0.68203 — 0.68375 | 82/91 90% | 2/11 18% | 80/80 100% |
| 0.54465 — 0.68201 | 83/91 91% | 3/11 27% | 80/80 100% |
| 0.51777 — 0.54463 | 82/91 90% | 3/11 27% | 79/80 99% |
| 0.43039 — 0.51775 | 83/91 91% | 4/11 36% | 79/80 99% |
| 0.42374 — 0.43037 | 84/91 92% | 5/11 45% | 79/80 99% |
| 0.34390 — 0.42372 | 85/91 93% | 6/11 55% | 79/80 99% |
| 0.30136 — 0.34388 | 86/91 95% | 7/11 64% | 79/80 99% |
| 0.29007 — 0.30134 | 85/91 93% | 7/11 64% | 78/80 98% |
| 0.21795 — 0.29005 | 84/91 92% | 7/11 64% | 77/80 96% |
| 0.17878 — 0.21793 | 83/91 91% | 7/11 64% | 76/80 95% |
| 0.14962 — 0.17876 | 82/91 90% | 7/11 64% | 75/80 94% |
| 0.12181 — 0.14960 | 83/91 91% | 8/11 73% | 75/80 94% |
| 0.11997 — 0.12179 | 84/91 92% | 9/11 82% | 75/80 94% |
| 0.11189 — 0.11995 | 83/91 91% | 9/11 82% | 74/80 93% |
| 0.11051 — 0.11187 | 82/91 90% | 9/11 82% | 73/80 91% |
| 0.10711 — 0.11049 | 81/91 89% | 9/11 82% | 72/80 90% |
| 0.07635 — 0.10709 | 82/91 90% | 10/11 91% | 72/80 90% |
| 0.07314 — 0.07633 | 81/91 89% | 10/11 91% | 71/80 89% |
| 0.04475 — 0.07312 | 80/91 88% | 10/11 91% | 70/80 88% |
| 0.04416 — 0.04473 | 79/91 87% | 10/11 91% | 69/80 86% |
| 0.04364 — 0.04414 | 78/91 86% | 10/11 91% | 68/80 85% |
| 0.04031 — 0.04362 | 77/91 85% | 10/11 91% | 67/80 84% |
| 0.03637 — 0.04029 | 76/91 84% | 10/11 91% | 66/80 83% |
| 0.03294 — 0.03635 | 75/91 82% | 10/11 91% | 65/80 81% |
| 0.02897 — 0.03292 | 74/91 81% | 10/11 91% | 64/80 80% |
| 0.02749 — 0.02895 | 73/91 80% | 10/11 91% | 63/80 79% |
| 0.02566 — 0.02747 | 72/91 79% | 10/11 91% | 62/80 78% |
| 0.02482 — 0.02564 | 71/91 78% | 10/11 91% | 61/80 76% |
| 0.02323 — 0.02480 | 70/91 77% | 10/11 91% | 60/80 75% |
| 0.02319 — 0.02321 | 71/91 78% | 11/11 100% | 60/80 75% |
| 0.00001 — 0.02317 | 64-70/91 70-77% | 11/11 100% | 53-59/80 66-74% |
Limitations of This Approach — Computational Complexity and Botnets
The first problem that comes to mind is the computational complexity of applying this to large collections of attack sequences. The eventual goal would be to answer for a newly observed sequence, Does this sequence strongly resemble anything seen so far? That would require an approach based on a feature vector, so the only new computation would be the calculation of the new feature vector and a comparison to an existing catalog of observed attack signatures. Analysis using the other inter-document similarity measures would require calculation growing with the size of the existing data collection.
An unexpected problem arose when applying this this same
sort of sequence extraction and analysis to a new month's
data.
That data included an attack by a botnet
of 707 hosts in which only guesses for
the root password were attempted.
Start: Nov 19 15:00:42 End: Nov 21 03:18:36 Duration: 36:17:54 Guesses: 2666
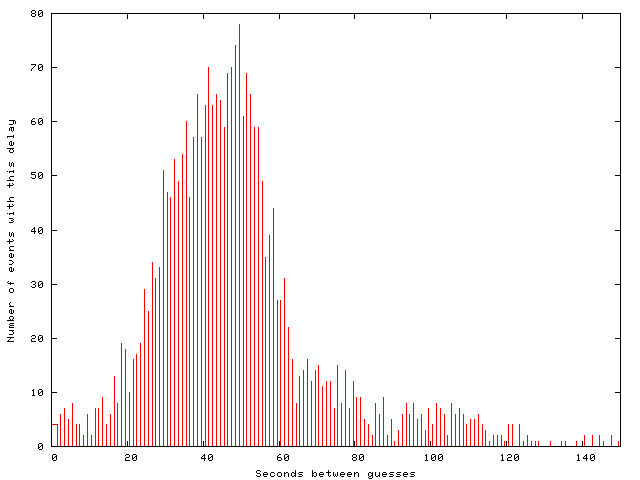
Typical guesses were separated by 20 to 80 seconds
from the one before.
With two exceptions, no botnet members made two consecutive
guesses.
A gnuplot
histogram of the inter-guess times
shows the distribution.
Click here to see the list of botnet members and the inter-attack timing.
The SSH daemon and the PAM modules it uses only
log the event of a failure.
Sniffing packets can show the host-to-host
handshaking, in which every client identified itself as:
SSH-2.0-libssh-0.2,
immediately suggesting that this was a botnet, all the
members running C code compiled against the libssh API.
However, once the hosts attempt host-to-host authentication
(which, of course, fails in this case) and then negotiate
ciphers and a session key, you see nothing else useful
in the raw network traffic.
The trick is to attach to the SSH server process with
strace and observe the I/O at the application
level.
First, find the process ID of the listening SSH server.
Run this command:
lsof -i tcp:ssh
and look for the PID of the process marked LISTEN.
Second, if that PID were 12345, run this command as
root:
strace -f -e 'read,write' -p12345
This page
claims to list "The Top 500 Worst Passwords of All Time",
but there is no explanation of where they got that data.
Since admin isn't even on the list despite being
the default password on lots of network gear, I don't think
the list is very authoritative.
But it's kind of interesting.
Coming in mid-attack, I saw an alphabetical list of names
and words being used as root password guesses:
dominique
domino
dontknow
doogie
doors
dork
doudou
doug
downtown
dragon1
driver
and so on.
Some further analysis showed that this sequence
had been used as as target logins for password guesses
within two earlier attacks,
click here to see the Linux/UNIX command-line
trick to easily find these.
Those attacks were separated by 77 days,
and the two attacking hosts were in Brazil and Germany:
| Attacker | Target | Start | End | Password guesses for: | |||
| root | non-root | invalid users | all users | ||||
| 200.213.105.90 c8d5695a.static.cps.virtua.com.br. inetnum: 200.213.105/24 owner: TV CABO DE PORTO ALEGRE LTDA responsible: Grupo de Seguranca da Informacao Virtua country: BR |
x053 | Mar 16 10:32:36 | Mar 16 13:27:24
10488 seconds |
5 / 5 | 2807 / 2806 |
2812 / 2811
3.73 sec/guess |
|
| i192 | Mar 16 10:32:37 | Mar 16 13:28:57
10580 seconds |
4 / 4 | 2850 / 2849 |
2854 / 2853
3.71 sec/guess |
||
| c193 | Mar 16 10:32:38 | Mar 16 13:28:05
10527 seconds |
4 / 4 | 2810 / 2809 |
2814 / 2813
3.74 sec/guess |
||
| a201 | Mar 16 10:32:39 | Mar 16 13:26:45
10446 seconds |
4 / 4 | 2816 / 2815 |
2820 / 2819
3.71 sec/guess |
||
| a202 | Mar 16 10:32:41 | Mar 16 13:26:45
10444 seconds |
4 / 4 | 2811 / 2810 |
2815 / 2814
3.71 sec/guess |
||
| a204 | Mar 16 10:32:51 | Mar 16 13:26:45
10434 seconds |
4 / 4 | 2807 / 2806 |
2811 / 2810
3.71 sec/guess |
||
| a203 | Mar 16 10:32:57 | Mar 16 13:26:42
10425 seconds |
4 / 4 | 2762 / 2761 |
2766 / 2765
3.77 sec/guess |
||
| a205 | Mar 16 10:32:58 | Mar 16 13:26:40
10422 seconds |
4 / 4 | 2763 / 2762 |
2767 / 2766
3.77 sec/guess |
||
|
total: 8 targets 22459 probes |
Mar 16 10:32:36 | Mar 16 13:28:57
10581 seconds |
33 / 6 | 22426 / 2850 |
22459 / 2853
0.47 sec/guess |
||
| Attacker | Target | Start | End | Password guesses for: | |||
| root | non-root | invalid users | all users | ||||
| 85.114.130.49 kd14.ab-webspace.de. inetnum: 85.114.128.0 - 85.114.135.255 netname: FASTIT-DE-DUS1-COLO4 descr: fast IT Colocation country: DE address: fast IT GmbH address: Am Gatherhof 44 address: 40472 Duesseldorf address: DE address: fibre one networks GmbH address: Network Operations & Services descr: DE-FIBRE1-85-114-128-0---slash-19 descr: DE-FIBRE1-85-114-128-0---slash-20 |
s120 | Jun 1 15:49:25 | Jun 1 18:03:18
8033 seconds |
4 / 4 | 2394 / 2393 |
2398 / 2397
3.35 sec/guess |
|
| x053 | Jun 1 15:49:28 | Jun 1 15:49:28 | 1 / 1 | 1 / 1 | |||
| t121 | Jun 1 15:54:37 | Jun 1 18:03:21
7724 seconds |
4 / 4 | 2303 / 2302 |
2307 / 2306
3.35 sec/guess |
||
| a201 | Jun 1 15:56:06 | Jun 1 18:03:18
7632 seconds |
4 / 4 | 2264 / 2263 |
2268 / 2267
3.37 sec/guess |
||
| c193 | Jun 1 15:56:07 | Jun 1 15:56:07 | 1 / 1 | 1 / 1 | |||
| i192 | Jun 1 15:56:08 | Jun 1 15:56:08 | 1 / 1 | 1 / 1 | |||
| a203 | Jun 1 15:56:22 | Jun 1 16:15:02
1120 seconds |
334 / 334 |
334 / 334
3.36 sec/guess |
|||
| a204 | Jun 1 16:05:33 | Jun 1 18:03:19
7066 seconds |
4 / 4 | 2092 / 2091 |
2096 / 2095
3.37 sec/guess |
||
| a202 | Jun 1 16:29:10 | Jun 1 18:03:18
5648 seconds |
3 / 3 | 1662 / 1661 |
1665 / 1664
3.39 sec/guess |
||
|
total: 9 targets 11071 probes |
Jun 1 15:49:25 | Jun 1 18:03:21
8036 seconds |
19 / 4 | 11052 / 2396 |
11071 / 2400
0.73 sec/guess |
||
The only differences within the sequences from 200.213.105.90,
in Brazil, on March 16, was early termination.
That is, compared to the 200.213.105.90->i192 sequence
of 2,854 logins, the others were identical until they
terminated slightly before the end.
And that longest sequence probably terminated itself early,
stopping at virago within one of several alphabetical
subsequences:
..., vicki, vicky, victor1, vikram, vincent1,
violet, violin, virago
Comparing the 200.213.105.90->i192 sequence to the sequences from the attack from 85.114.130.49, in Germany, on June 1, we see that they are basically the same sequences. The differences are early termination plus deletion of a few entries mid-list, probably due to timeouts during that attack.
That 200.213.105.90->i192 sequence is the most complete version of this list seen in two attack sequences widely separated in time and space, click here to see that list.
That sequence appears to be a list of likely passwords
rather than logins.
Just look at the first 10:
12345 abc123 password computer 123456
tigger 1234 a1b2c3 qwerty 123
Users usually aren't assigned identities like those,
but they are the sorts of passwords users
would prefer!
| To derive from 200.213.105.90->i192 sequence | ||
| Attacking host | Target | Changes required to produce the observed sequence |
| 85.114.130.49 | s120 |
Delete entries #1177, 2088, 2110:
lisa, gigi, gretaTerminate early |
| 85.114.130.49 | t121 |
Delete entries #1019, 1086, 1475:
creative, gasman, 181818Terminate early |
| 85.114.130.49 | a201 |
Delete entries #639, 659, 1073, 1698:
godzilla, imagine, florida, aprilTerminate early |
| 85.114.130.49 | a203 |
Delete entry #310:
morganTerminate early |
| 85.114.130.49 | a204 |
Delete entries #471, 491, 1270:
rosebud, sunny, pennyTerminate early |
| 85.114.130.49 | a202 |
Delete entries #48, 132, 391, 1360, 1445:
bear, biteme, explorer, snowflake, xcountryTerminate early |
Also recall that the target hosts are shown here as the first letter of the host name followed by a 3-digit representation of the last octet of the IP address. The first attack sequence started in numerical order if we disregard one entry transposed by one position, suggesting that the attacks were driven by a list or range of IP addresses or a CIDR representation. That makes sense, as none of the hosts are public web servers or other prominent hosts. The starting order of the second attack makes less sense, as the target hosts are ordered by neither host name nor IP address. The organization's DNS servers do not allow zone transfers, so an attacker could not have obtained a list of host names that way. Also, some of the systems involved are used only as servers, and so they would not have shown up as clients in some web server's logs. The only thing that really makes sense is for these attacks to have been controlled by ranges of IP addresses.
| Attacker | IP address sequence |
| 200.213.105.90 | xxx.yyy.zzz.053, 192, 193, 201, 202, 204, 203, 205 |
| 85.114.130.49 | xxx.yyy.zzz.120, 053, 121, 201, 193, 192, 203, 204, 202 |
The timing between the starts of the individual sequences also varied between the two attacks. Maybe the order and start times were randomized by the attack software.
| Attacker | Seconds between attack sequence starts |
| 200.213.105.90 | 1, 1, 1, 2, 10, 6, 1 |
| 85.114.130.49 | 3, 309, 89, 1, 1, 14, 551, 1417 |
A similar attack from a larger botnet was seen when analyzing data from two servers at a web hosting company.
These attacks show the impracticality of purely automated analysis. My analysis script can generate an HTML file describing a month's probes against a system. But the file grows proportionally when one botnet attack appears to be hundreds of one-guess attacks. What had been an HTML file of a few hundred kilobytes grows into the tens of megabytes with the addition of all those tables.
It seems that human judgement is needed to tell the difference
between an unaggressive botnet and random one-guess attacks.
More difficult yet is the situation where a more
aggressive single-attacker sequence happens to fall in the
middle of a botnet attack.
Several did, in this case, but they were spotted by seeing
how many consecutive guesses were made by each host.
This can be done with use of a simple
uniq | sort -n command sequence.
Given an average inter-guess timing in the tens of seconds
for the botnet versus two to four seconds for a typical
single host, the non-botnet hosts stood out and could be
removed from consideration.
Attack #1: Start: Nov 14 18:35:24 Nov 14 18:35:24 End: Nov 16 20:52:18 Nov 16 20:52:16 Duration: 50:16:54 50:16:52 Guesses made: 882 872 Unique logins: 85 83 Botnet members: 306 309 Target host: c193 i192 Attacking hosts in common: 303 Attack #2: Start: Nov 18 07:32:06 Nov 18 07:32:06 End: Nov 18 18:41:57 Nov 18 18:41:57 Duration: 03:09:51 03:09:51 Guesses made: 142 144 Unique logins: 42 42 Botnet members: 101 102 Target host: c193 i192 Attacking hosts in common: 101
Motivated to look for signs of botnets, two more attacks
were spotted against other hosts during that same month!
Those attacks seem to have been perpetrated by the same
botnet, as there is a large overlap in their member hosts.
The attacks were rather different than those of the first
botnet, as they attempted guesses for a number of accounts
in addition to root.
Logins attacked in sequence #1:
admin allison amanda andy at backup backup1 cathy cecilia
charles christoph cookie cpanel crystal cs data ed
frances ftp ftpuser games glenn irc jacki james jan
jennifer joe john jon justin kevin kim knoppix ldap
leonard lillian majordom mark martin matt melissa
michel murphy mysql nagios nikki office oracle paul
porter postgres postgress qmail rex richard robby
robert root samba security steve test test1 test2
test3 test4 todd tomcat ts ts2 web0 web1 web2 web3
web4 web5 web6 web7 webmaster webmin wilson
yolanda zach zope
Logins attacked in sequence #2:
amavis amavisd apache clamav contacts cyrus demo demo1
demo3 dhcpd fetchmail games gnats guest lp mail news
spam squid student stunnel suse-ncc tcpdump test3
user user1 vscan web0 web1 web10 web11 web12 web13
web2 web3 web4 web5 web7 web8 web9 www wwwrun
Comparing the sets of attacking hosts (the botnet members), 94 were seen in both attack sequences. As seen in this table, the distribution of activity varied between the two attacks. The numbers in the table record the number of password guesses, individual attacks or probes, and does not necessarily reflect the number of unique botnet members in that country.
| Botnet probes by country | Attack #1 | Attack #2 | ||
| c193 | i192 | c193 | i192 | |
| US, United States | 124 | 124 | 20 | 20 |
| DE, Germany | 122 | 121 | 10 | 10 |
| IT, Italy | 67 | 65 | 9 | 9 |
| PL, Poland | 58 | 58 | 8 | 9 |
| BR, Brazil | 51 | 49 | 11 | 11 |
| IE, Ireland | 40 | 40 | 1 | 1 |
| FR, France | 37 | 37 | 11 | 11 |
| ES, Spain | 34 | 33 | 6 | 6 |
| RO, Romania | 34 | 33 | 5 | 5 |
| CZ, Czech Republic | 27 | 24 | 5 | 5 |
| AT, Austria | 25 | 25 | 1 | 1 |
| GB, United Kingdom | 25 | 25 | 8 | 9 |
| NL, Netherlands | 21 | 20 | 1 | 1 |
| AR, Argentina | 18 | 18 | 2 | 2 |
| MX, Mexico | 18 | 18 | 5 | 5 |
| HU, Hungary | 17 | 17 | 2 | 2 |
| RU, Russian Federation | 17 | 15 | 2 | 2 |
| CO, Colombia | 15 | 15 | 2 | 2 |
| BE, Belgium | 16 | 15 | 3 | 3 |
| SE, Sweden | 15 | 15 | 0 | 0 |
| CH, Switzerland | 14 | 13 | 1 | 1 |
| CL, Chile | 12 | 12 | 4 | 4 |
| UA, Ukraine | 12 | 12 | 0 | 0 |
| DK, Denmark | 11 | 11 | 2 | 2 |
| TR, Turkey | 9 | 9 | 1 | 1 |
| SK, Slovakia | 7 | 7 | 0 | 0 |
| PE, Peru | 6 | 6 | 4 | 4 |
| SV, El Salvador | 6 | 6 | 0 | 0 |
| GT, Guatemala | 5 | 5 | 0 | 0 |
| HK, Hong Kong | 5 | 5 | 0 | 0 |
| IL, Israel | 5 | 5 | 2 | 2 |
| LT, Lithuania | 5 | 5 | 0 | 0 |
| TW, Taiwan | 5 | 5 | 2 | 2 |
| CA, Canada | 4 | 4 | 1 | 1 |
| AU, Australia | 3 | 3 | 2 | 2 |
| BG, Bulgaria | 3 | 3 | 0 | 0 |
| CN, China | 3 | 2 | 1 | 1 |
| EE, Estonia | 3 | 3 | 2 | 2 |
| ZA, South Africa | 3 | 3 | 1 | 1 |
| cannot resolve | 3 | 3 | 0 | 0 |
| CI, Cote D'Ivoire | 2 | 4 | 1 | 1 |
| IN, India | 2 | 2 | 0 | 0 |
| JP, Japan | 2 | 2 | 0 | 0 |
| PT, Portugal | 2 | 2 | 0 | 0 |
| ID, Indonesia | 1 | 2 | 1 | 1 |
| KR, Korea, Republic of | 1 | 1 | 2 | 2 |
| LA, Lao People's Democratic Republic | 1 | 1 | 0 | 0 |
| LK, Sri Lanka | 1 | 1 | 0 | 0 |
| MY, Malaysia | 1 | 1 | 0 | 0 |
| RS, Serbia | 1 | 1 | 0 | 0 |
| UZ, Uzbekistan | 1 | 2 | 0 | 0 |
| VE, Venezuela | 1 | 1 | 0 | 0 |
Some stereotypes are reinforced in that table: the high rankings of the U.S. and Europe. Others are dashed: the surprisingly low rankings of China, Hong Kong, and Japan.
Within each of the two attacks, the distributions of probe sources seen on the two target hosts were almost identical. The slight differences were probably due to timeouts leading to abandoned attempts.
For more details, extracts of the logs are available.
These show the full sequence of guesses made by each
botnet, showing the timestamp, login guessed,
and botnet member making that guess:
•
Attack #1, target = c193
•
Attack #1, target = i192
•
Attack #2, target = c193
•
Attack #2, target = i192
The timing was less aggressive in these smaller attacks, as shown by the inter-attack timing histograms below. Attacks in the first and second sequences were spaced by 100-200 seconds and about 200 seconds, respectively.
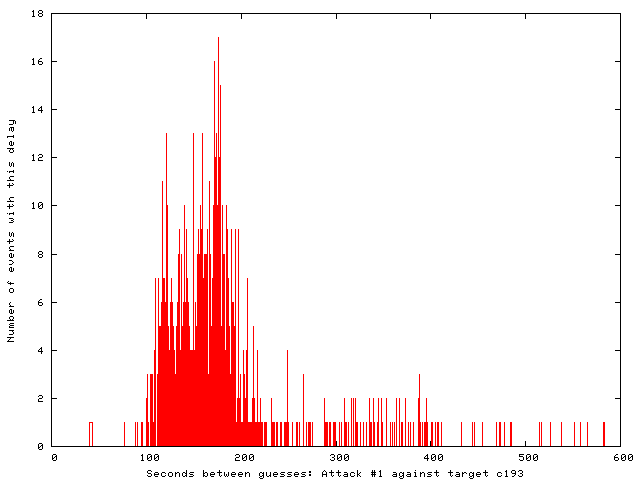
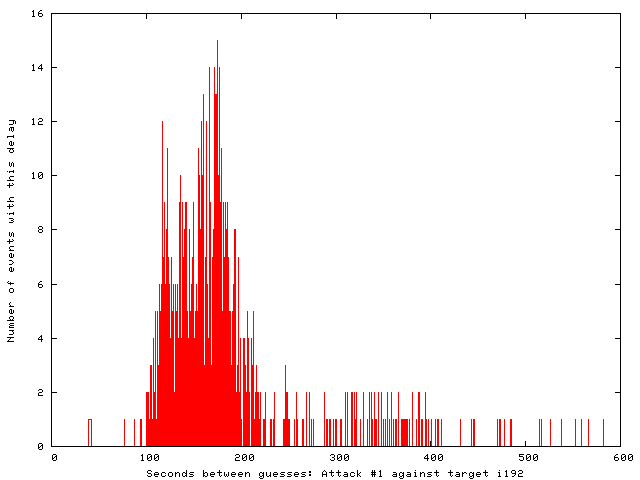
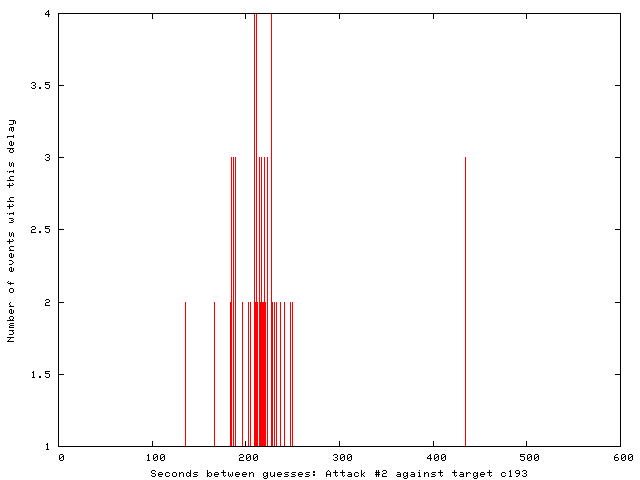
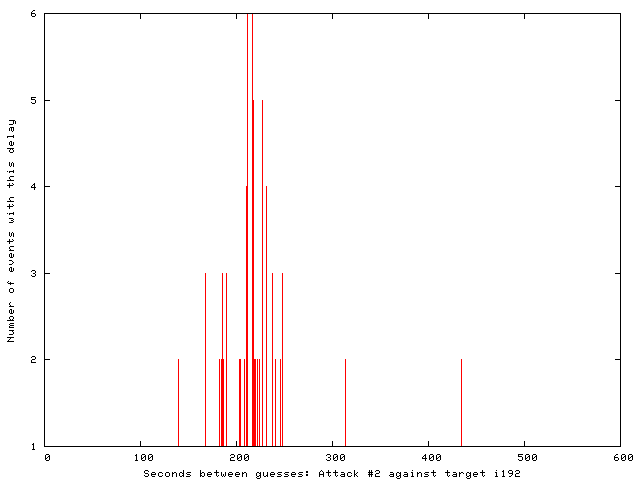
To generate those histograms of inter-attack timing, start with a file "botnet-times" containing one inter-attack time per line:
% awk '{print $1}' botnet-list > botnet-times
% cat > histo.gnuplot << EOF
set style data line
set boxwidth 3
set xlabel "Seconds between guesses"
set ylabel "Number of events with this delay"
set xrange [0:150]
set key off
set term png
set output 'timing-histogram.png'
bw = 1
bin(x,width) = width*floor(x/width)
plot 'botnet-times' using (bin($1,bw)):(1.0) smooth freq with boxes
EOF
% gnuplot histo.gnuplot
Other Work
"Entropy estimation of symbol sequences"
Thomas Schuermann and Peter Grassberger
Abstract:
"We discuss algorithms for estimating the Shannon entropy h
of finite symbol sequences with long range correlations.
In particular, we consider algorithms which estimate h
from the code lengths produced by some
compression algorithm.
Our interest is in describing their convergence with
sequence length, assuming no limits for the space and
time complexities of the compression algorithms.
A scaling law is proposed for extrapolation from
finite sample lengths.
This is applied to sequences of dynamical systems
in non-trivial chaotic regimes, a 1-D cellular
automaton, and to written English texts."
"Syntactic Clustering of the Web"
Andrei Z. Broder, Steven C. Glassman, Mark S. Manasse,
and Geoffrey Zweig,
SRC Technical Note 1997-015
Abstract:
"We have developed an efficient way to determine the
syntactic similarity of files and have applied it
to every document on the World Wide Web.
Using this mechanism, we built a clustering of all
the documents that are syntactically similar.
Possible applications include a "Lost and Found"
service, filtering the results of Web searches,
updating widely distributed web-pages,
and identifying violations of
intellectual property rights."
"Finding Similar Files in
a Large File System"
Udi Manber, TR 93-33, University of Arizona
Abstract:
"We present a tool, called sif, for finding all
similar files in a large file system.
Files are considered similar if they have
significant number of common pieces, even if they
are very different otherwise.
For example, one file may be contained,
possibly with some changes, in another file,
of a file may be a reorganization of another file.
[....]"
"Clustering and Categorization
Applied to Cryptanalysis"
Claudia Oliveira,
José Antônio Xexéo,
Carols André Carvalho,
Cryptologia
v30, n3, pp 266-280, 2006
A nice discussion of a generalized clustering approach
and its application to cryptanalysis.
"Stylistic Text Classification Using
Functional Lexical Features"
Shlomo Argamon, Casey Whitelaw, Paul Chase,
Sobhan Raj Hota, Navendu Garg, and Shlomo Levitan,
Journal of the American Society for Information Science
and Technology
vol 58, no 6, pp 802-822, 2007
Abstract:
"Most text analysis and retrieval work to date has focused
on the topic of a text; that is, what
it is about.
However, a text also contains much useful information
in its style, or how it is written.
This includes information about its author, its
purpose, feelings it is meant to evoke, and more.
This article develops a new type of lexical feature
for use in stylistic text classification, based
on taxonomies of various semantic functions
of certain choice words or phrases.
We demonstrate the usefulness of such features for
the stylistic text classification tasks of
determining author identity and nationality,
the gender of literary characters, a text's
sentiment (positive/negative evaluation),
and the rhetorical character of scientific
journal articles. [....]"
"Evaluating Internet Resources: Identity, Affiliation,
and Cognitive Authority in a Networked World"
J. W. Fritch and R. L. Cromwell (yes, that's me),
JASIST (Journal of the American Society of
Information Science and Technology),
vol. 52, no. 6 (2001), pp 499-507.
In addition to referencing our JASIST paper, Argamon et al also list a number of other papers describing work on author attribution and profiling:
- "Gender, Genre, and Writing Style in Formal Written Texts", Argamon, Koppel, Fine, and Shimony, Text, 23(3), 321-346, 2003.
- "Outside the Cave of Shadows: Using Syntactic Annotation to Enhance Authorship Attribution", Baayen, Halteren, and Tweedie, Literary and Linguistic Computing, 7, 91-109, 1996.
- "Computation into Criticism: A Study of Jane Austen's Novels and an Experiment in Method", J.F. Burrows, Clarendon Press, Oxford, England, 1987.
- "Language and Gender Author Cohort Analysis of E-mail for Computer Forensics", de Vel, Corney, Anderson, and Mohay, in Proceedings of the Digital Forensic Research Workshop, Syracuse, NY, pp 7-9, 2002.
- "Visualization of Literary Style", Kjell and Frieder, in Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Chicago, IL, pp 656-661, 1992.
- "Authorship Studies/Textual Statistics", McEnery and Oakes, in Handbook of Natural Language Processing, Dale, Moisl, and Somers, editors, Dekker, Philadelphia, 2000.
- "Inference and Disputed Authorship: The Federalist", Mosteller and Wallace, Addison-Wesley, Reading MA, 1964.
- "Automatic Text Categorization in Terms of Genre, Author," Stamatatos, Fakotakis, and Kokkinakis, Computational Linguistics, 26(4), pp 471-495, 2000.
- "A Probabilistic Similarity Metric for Medline Records: A Model for Author Name Disambiguation", Torvik, Weeb, Swanson, and Smalheiser, Journal of the American Society for Information Science and Technology, 56(2), pp 140-158, 2005.
To The Security Page