Bob's Blog
What is this "A.I." or "Artificial Intelligence"?
What is the currently popular "Artificial Intelligence" or "A.I."?
I put it in so-called "quotation marks" because it isn't really intelligence. It is, at best, Simulated Intelligence.
The short version: Text generation systems are based on a "next word predictor" engine. Automated statistical analysis of large collections of text allow it to generate output that mostly forms proper grammar. Given an appropriate start, the resulting text can seem to be a plausible discussion of the topic. Image and video generation uses analogous techniques for multidimensional data.
Yes, neural nets have been around for 50+ years. Markov chain models for text prediction and generation are at least as old. GPU hardware has allowed things to scale up, but haven't really brought new concepts.
The claims of "Artificial Intelligence" are hype. That leads to misuse of terms like "discover" and "understand", and then "hallucinate" to excuse when it goes more obviously off the rails.
The "A.I." systems make things up. That's all they do.
They can happen to be true, or describe possibly useful plans. But all that the systems really produce is output that looks plausible. It has the same statistical nature at varying scales, so the resulting text or images or video look realistic.
We humans are prone to seeing patterns that aren't there. Faces in clouds, the Virgin Mary in burned toast, and meaningful content in these systems' outputs.
The "A.I." systems seem to have problems with ear, teeth, and fingers. They tend to depict two eyes, one nose, and one mouth in the proper locations and alignments. Teeth end up an appropriate color and shape, but often far too many small teeth. I haven't seen example blunders with beyond-Gary-Busey giant square teeth but I'm sure they happen. There may be extra fingers, some too short or long. But statistically, the bogus teeth and fingers are reasonable. The teeth are white and square-ish, several aligned in a row. The fingers have reasonable individual shapes and alignments, and there are several of them. As for ears, they're only partially visible in most portraits anyway, and they're depicted as wrinkled protrusions of roughly oval overall shape.
My background? Why should you even consider what I say, or be skeptical, or refuse to listen? I did finish a Ph.D. about machine vision systems that could automatically learn (or discover) how to do object recognition tasks.
My approach tried to do automated generalization. Go from images to descriptions, not the reverse as currently popular. Shown collections of fruit that a human supervisor had divided into categories, maybe a system could discover rules that a machine could use to recognize images of fruit, ideally in a form that a human would find meaningful:
Grapes are small ellipsoids, colored light green through purple.
Watermelons are large green ellipsoids.
Blueberries are small dark blue spheres.
Raspberries are small clusters of very small nearly-black spheres.
Bananas are medium-sized yellow cylinders, but with curved major axes and tapered ends.
Oranges are medium-sized rough-surfaced spheres colored "orange".
Part of this was in response to a small heretical movement (maybe just one professor) that said that radiology instruction very likely was giving students bad guidance, and those who did better and specialized in the field had managed to discover their own rules.
Radiology is like chick-sexing.1 Some individuals become very good at it. But if you ask them exactly what they're doing, they can't explain it beyond the basic rules that everyone heard on the first day of training. Apparently they're applying some subconscious rules in addition to "tumor boundaries are more irregular" and the other classics. The heretical view said that additional, currently untaught, rules must exist, and if you would tell radiology students about them early in their training, then you could get more skilled radiologists faster. Maybe by more quickly distinguishing which students have the aptitude and which should specialize elsewhere.

I was in a robotics lab, trying to stay away from the robots as much as possible because they were terribly fussy about needing frequent tedious recalibration as to what angles all their joints were pointing, and for safety reasons they had to operate at slow speeds that made an experiment take hours.
My thing was the visual data collection and analysis. Let someone else try controlling a poky-yet-still-hazardous robotic arm based on my system's output.
"Analyzing sensor data" means doing some calculation (math) based on multiple measurements (numbers), yielding a collection of numbers that you call a "feature vector" for each object or surface in the scene. Maybe its length, width, curvatures, surface roughness, and dominant color are these five numbers, probably floating-point numbers instead of integers.
Collect feature vectors for several individual examples, and you can start to characterize how individual features vary, or don't, and how the variation of one is related to variation of one or more others.
Then repeat that for multiple classes of objects, and you're getting what you need to classify a new object. They will probably overlap in one or more features (grapes and blackberries are roughly the same size), but another feature (color, or surface roughness) can distinguish them. Or, more likely, some combination of features.
The premise was that sometimes we humans would benefit from descriptions that we find meaningful. Not a feature vector of floating-point numbers for one object, or a matrix of floating-point numbers describing the probabilities and the cross-correlations of individual features across the class. But instead, maybe we need an English sentence like the above ones about types of fruit.

Amazon 0312610491
"Meaningful to people" is awfully vague and ambiguous.
Those are English sentences.
What we call dark blue and light blue,
nothing more than brightness variations of the one color blue,
are two entirely distinct colors with their own names
to Russian and Greek speakers.
голубой
γαλάζιος
#00BFFF
синий
μπλε
#0000FF
But then what we English speakers insist are the two very distinct colors "blue" and "green" are just very slight variations of one color to speakers of Japanese, Thai, Vietnamese, Lakota Sioux, Mayan languages, Tibetan, Pashto, and others. Color boundaries are very language specific.
Blue Means GoIn Japan
Stoplights in Japan used to be red, yellow, and what I call "blue". Some international traffic safety organization put an end to that during the U.S. Occupation. Old walk signals in Japan are still what I call "blue". New ones are "green" because there isn't a large international market for blue LED signal lamps.

2 I used no chicken cloaca imagery in my thesis research. One of many shortcomings.
For some applications, like the radiology training, and I suppose the chick-sexing training, 2 the generalized description would still be of value even if it was somewhat less accurate at classifying newly-seen objects.
In a stunning failure of prediction, my thesis criticized the neural network approach to machine learning. It was and would remain useless because what it learned was in the form of large matrices of floating-point numbers, utterly meaningless to people. And it was hopeless to attempt because each input feature vector would have to be a fairly large collection of floating-point numbers. To be statistically useful, the dimensionality meant that you would need an enormous number of examples in the training data set.
Hence the "Large Language Model" or LLM. Scrape the Internet to model human language. Originally just public-domain works at Project Gutenberg, now all web pages and social media feeds.
All of that led to a neural network with an overwhelming number of nodes and links. Remember, a computer has a single i486 CPU with no "additional core(s)", its clock runs at 16 to 100 MHz, and it has a few megabytes of RAM.
Today, a GPU is like multiple CPUs with hundreds of cores and on-board high-speed RAM, and one OS may be running across an array of GPUs. The neural network model is much broader and deeper than those of 1990, hence "deep learning", but it works like the original proposal from 1972. Yes, it takes a lot of electrical power to do the learning, and a lot of cooling to keep the system from destroying itself. And, "what it has learned" is a collection of mysterious floating-point matrices. But the result can be very useful for classifying new data. Using the matrices for classifying or recognition takes far less power than creating the matrices during the training phase.
But now the "A.I." systems are being used as if the hype about them were really true. Scientific publication is getting hammered. Take China, where English skills may be limited and there are financial incentives to publish. A researcher has done something, and then tells an "A.I." system to generate a paper about their results. The automated system relies on a large body of example scientific writing, takes some fragments of the new work as a seed, and generates something incorporating those details into something generally scientific-looking. The researcher may also ask for images, which again will have statistic similarities to what might be real. But all of the text and images have been made up, that's all that these systems do.
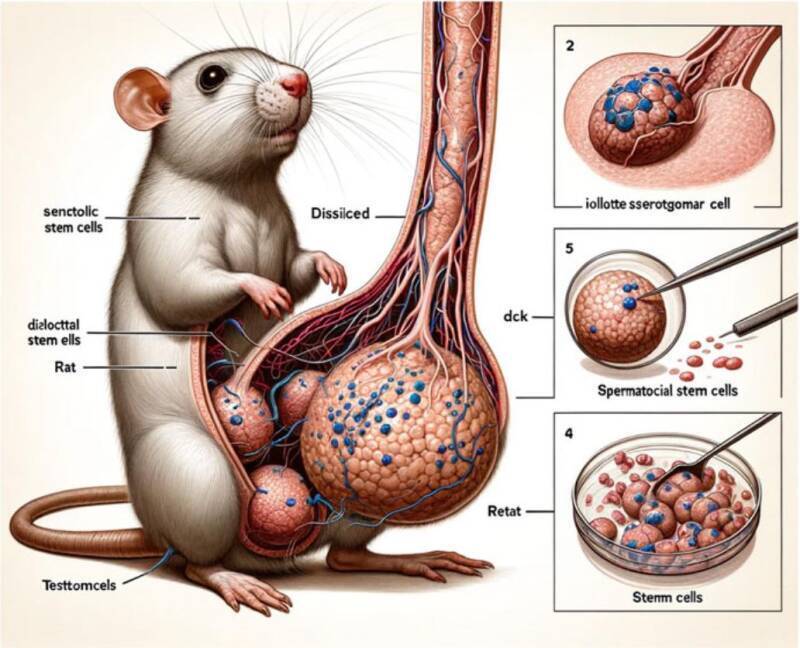
Consider these figures from an A.I.-generated paper that was published in a journal, which eventually became embarrassed enough to retract it.
Xinyu Guo, Liang Dong, and Dingjun Hao, "Cellular functions of spermatogonial stem cells in relation to JAK/STAT signaling pathway", Frontiers in Cell Development and Biology, vol 11, 2023, doi:10.3389/fcell.2023.1339390
The captions and labels resemble what you would find in a real English-language paper in that field, but only the one saying "Rat" in the first figure happened to be reasonable. The word "Rat" labels what mostly looks like a rat, although with abnormally long hind feet. Its topology is wrong — it seems to have an incision down the right side of its body while the furry exterior of its left side disappears into the interior. But then that other, larger thing is the nightmare of what we're supposed to interpret as genitalia...
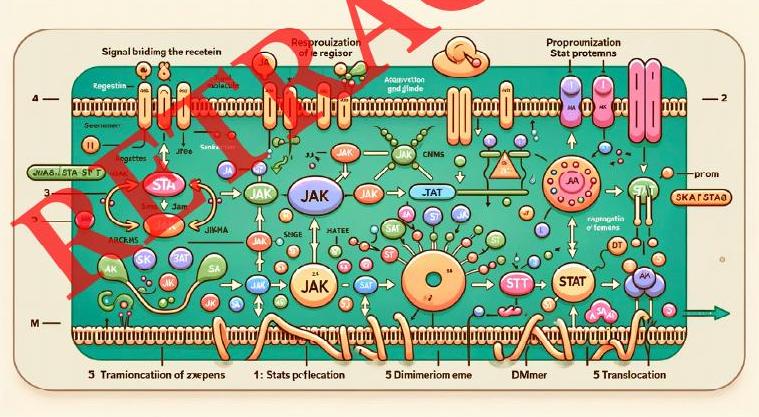
But hey, it got published in a "peer-reviewed journal". And so it was a win for the authors for a while. Go for tenure! That is, until the Internet ridiculed it and the journal put the big red "RETRACTED" on all pages as you see in Figure 2's depiction of "Signal biidimg the recetein", "Resprouization of le regisor", "Proprounization Stat protemns", and more.
For maximal effect, you submit that result to a journal that relies at least partially on automated analysis of submissions. The journal's program says "Yes, this is an English language scientific paper on such-and-such aspect of thus-and-such field", and human attention may be limited to reading the abstract.

Amazon 0767806808
But wait, it's getting worse. The tech bros deploy "A.I." systems to scrape the Internet and create web page content into which they can automatically insert advertising. Upload that content to web servers and let "A.I." systems ingest that as a model for the next generation of content. Repeat that enough, and the whole thing should spin completely out of control. The original meaningful information soon disappears and surviving models are based on random variations. See Michael Keaton's 1996 movie Multiplicity for the failure of the approximate-copy-of-the-approximate-copy model.
Computers have always been considered as somehow magical. Charles Babbage, who described the Analytical Engine in 1837 but never got around to building it, said "On two occasions, I have been asked [by members of Parliament], 'Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?' I am not able to rightly apprehend the kind of confusion of ideas that could provoke such a question."
There have been multiple "A.I. Winters" caused by cycles of hype leading to intense disappointment and criticism and cuts in funding. We might be approaching another, which will have much more public impact because the currently hyped systems are being recklessly deployed. See the Wikipedia article "AI Winter" for a good overview. And, the New Yorker article "ChatGPT is a Blurry JPEG of the Web". For a technical analysis of the recursive problem see the Machine Learning paper "The Curse of Recursion: Training on Generated Data Makes Models Forget" on the model collapse.
On the positive and realistic side of things, there's the Purdue Institute for Drug Discovery. It's in the large biomedical campus that has grown up south of State Street, roughly from the Vet School at the southeast through the former site of Terry Courts at the northwest. One thing they do is automatically model complex biochemicals based on how molecules can be assembled. Calculate the resulting 3-D shape of the molecule, and see if that might fit some other chemical on the surface of a human cell, or on a microorganism.
Molecules that seem like they could have some promise get further study. Eventually, synthesize the most promising and try them in a petri dish of microorganisms. Then trials in fruit flies, mice, and humans, or whatever testing sequence is appropriate.
The computers behind the initial search are doing a lot of simulated biochemistry and 3-D molecular modeling. But Purdue isn't claiming (I hope!) that the computers are "creating drugs", or "designing drugs", or "understanding" chemistry or medicine, or "hallucinating" potential drugs. It's simulated chemistry and physics, and then calculated geometry, and claims of artificial consciousness.
Meanwhile the tech bros behind the "A.I." hype are saying "Of course we're brilliant and our computers are actually intelligent!" as they deploy slapped-together systems. It's monetizable, and corporations now have an excuse to fire all their customer support and help desk staff. And so it goes in the short term, until the tech bros have to retreat into their fortified bunkers.
Next:
10 Billion Passwords, What Does It Mean?
RockYou2024 is a list of 10 billion unique leaked passwords. Let's analyze what that really means.
Latest:
The Recurring Delusion of Hypercomputation
Hypercomputation is a wished-for magic that simply can't exist given the way that logic and mathematics work. Its purported imminence serves as an excuse for AI promoters.
Previous:
Books I've Read: "The Origin of Consciousness in the Breakdown of the Bicameral Mind"
According to the author, humans only became truly conscious in the second millennium BCE, and schizophrenia may be a holdover or return to the pre-conscious state.
Easy Automation of Thousands of Changes
Use fundamental Linux commands and some shell syntax to make thousands of changes in thousands of files in seconds.
What's Up With My Social Media Postings?
I have an automated Mastodon identity that posts numerous factoids of widely varying relevance. What's going on?.
Why I Abandoned OpenBSD
OpenBSD is technically OK but I won't be involved with, or appear to support, such a toxic environment.
1 As in the specialty of the three Japanese gentlemen who briefly lived in the boarding house across from my dad's home near Louisville when he was a little boy. Sorting new-born chicks at the poultry farm through the week, visiting all the bridges and dams across the Ohio River every weekend. Then disappearing with no explanation shortly before the autumn of 1941.