
Performance Tuning on Linux — Applications
Measure Application Resource Utilization
We need to measure at different scales of time
and breadth across the system.
We need individual snapshot measurements to capture
a current state.
We also need to monitor activity over time.
For example, top to monitor activity and identify
possible problems,
and then ps to further investigate some processes.
For storage I/O, we might start with system-wide monitoring
with vmstat and see that there seems to be
some problem.
Then use iostat to see which file systems the
problem is within.
Then use iotop to see which processes are
responsible.
Monitor the Process Table with top
By default top will refresh its display
every 3 seconds.
This is a reasonable tradeoff, as the CPU is very fast
so small sampling windows make sense,
but displayed information moves around and changes and you
need a chance to read something.
You can adjust this with -d,
including fractional timing.
So -d 0.2 for 5 measurements per second
to catch the thing that locks up your system.
Here is a workstation running BOINC scientific compute jobs at very low priority (39, larger means lower priority) and with Firefox reloading 20 tabs simultaneously. The output starts with a system summary and then a table of processes. By default it sorts by CPU utilization. This is a 4-core system, so expect %CPU plus idle to sum to 400%.
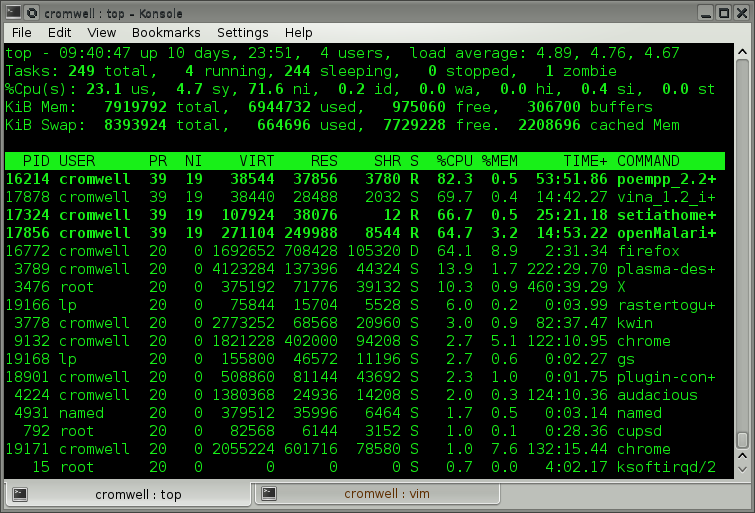
You can change the column by which the output is sorted with
< and >.
For example, press > once to sort by
percentage of physical memory.
Press 1 to toggle between one line summarizing
all CPU statistics, versus one line per core.
VIRT is total KiB of virtual memory allocated to the process. All code, data, and shared memory.
RES is KiB of physical memory currently in use by the process.
SHR is KiB of shared memory which should be shared with other processes (pages holding shared library code).
If you want to save just one screen into a file or send it into another command's standard input, use the following for batch mode, just one screen:
$ top -b -n 1
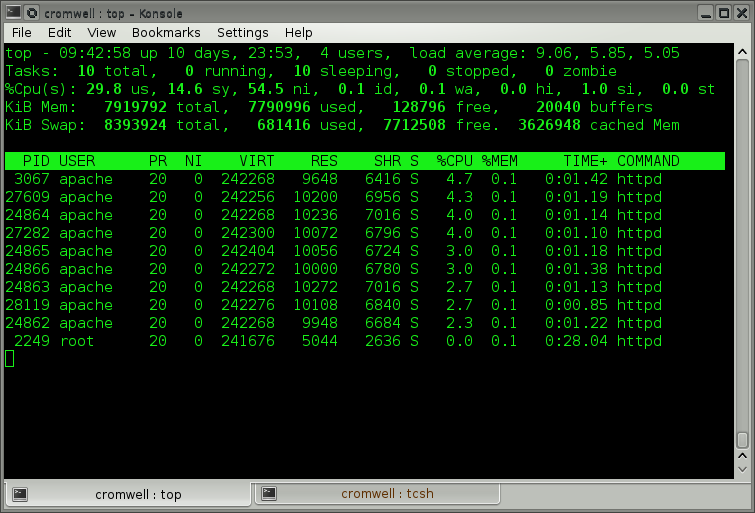
Ask for one or more processes with
-p PID[,PID2,...].
Here are just the Apache httpd daemons on a
heavily loaded web server.
The total CPU use isn't that much,
but we will see below that disk I/O is saturated.
# top -p $( pgrep -d, httpd )
sar andsysstat Examples
The sysstat package and sar command
can automatically collect and present information about
system activity.
It's a useful alternative to periodic captures with
top in batch mode.
Measure the Process Table with ps and pstree
Traditionally there have been two ps commands
to measure the running processes.
The SVR4 version used a POSIX-compliant dash with its options,
the BSD version did not.
The BSD version was usually more useful.
SunOS and then Solaris provided both with
/bin/ps and /usr/ucb/ps so the
order of your PATH environment variable gave you one or the
other by default.
The GNU version of ps supports both,
deciding which behavior to use based on whether
you use a dash.
Yes, you can mix both BSD and SVR4 options,
the command will try to figure out a way of
satisfying what you asked for and the result may
be useful.
These are the BSD and SVR4 ways of asking "Show me the
full process table."
The options include ww and -l meaning
wide (or long) output.
The order of the options don't matter and these are just
my habits.
Try these on your systems, these are impractical to display
on a web page:
$ ps axuww $ ps -elf
You can ask for a "family tree" tracing the heritage of
running processes.
You can do this with the ps command
or use the specially built pstree.
$ ps axf $ pstree -pl
You can accomplish an enormous variety of things with
ps, explore its
man page
to learn much more.
Monitor Process and Gross I/O Activity with vmstat
The vmstat command was intended to tell us
about virtual memory use, as its name suggests.
It isn't terribly useful for that directly,
but it does show us about things bound by virtual memory.
The important thing about vmstat is
learning what to ignore.
The first line of output is meant to be average since boot
time, that is seldom of interest and I have more recently
read that the data is not trustworthy even if you wanted it.
Ignore the first line.
Tell it how often to report with the number of seconds.
If you want only a certain number of reports,
specify that as a second number.
Or just interrupt it with ^C.
Here is example output for an overloaded system.
I started this monitoring in one window, using -t
to get timestamps.
I removed YYYY-MM-DD from the timestamps and aligned
columns for readability.
During the period shown in yellow I ran something in
another window to overload the system.
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- -timestamp- r b swpd free buff cache si so bi bo in cs us sy id wa st EDT 5 0 978372 3419936 131640 1076876 0 0 106 302 11 7 96 1 3 0 0 11:01:27 4 0 978372 3415988 131672 1077256 0 0 38 12 4564 2331 99 1 0 0 0 11:01:37 5 0 978372 3559760 131696 1077908 0 0 62 19 4524 2184 99 1 0 0 0 11:01:47 4 0 978372 3554256 131736 1078100 0 0 20 21 4561 2291 99 1 0 0 0 11:01:57 5 10 978372 2203908 131800 2295988 0 0 1474 44178 5422 5743 91 9 0 0 0 11:02:07 5 10 978372 1443300 131868 2821232 0 0 1048 58320 5322 5601 95 5 0 0 0 11:02:17 4 11 978372 767524 131964 3445876 0 0 3372 72039 6000 7913 91 9 0 0 0 11:02:27 8 8 978372 140056 130624 3958380 0 0 5369 81792 6684 9957 89 11 0 0 0 11:02:37 4 11 978372 142208 71300 4013620 0 0 7189 68877 5903 7457 91 9 0 0 0 11:02:47 5 13 978372 143936 71556 3972680 16 0 6786 69118 5630 6301 92 8 0 0 0 11:02:57 4 11 978372 125032 71752 3966480 76 0 6150 62090 5188 4565 95 5 0 0 0 11:03:07 10 4 978372 138400 72732 3850052 0 0 5335 74463 5622 6260 92 8 0 0 0 11:03:17 4 0 978372 692808 79072 3773836 0 0 2702 41704 5464 5608 94 6 0 0 0 11:03:27 4 0 978372 686028 79224 3774284 0 0 51 13202 4549 2124 98 1 0 0 0 11:03:37 4 0 978372 615416 79772 3775268 0 0 113 28 4721 2580 99 1 0 0 0 11:03:47 4 0 978372 546484 79828 3775640 0 0 39 28715 4599 2160 98 1 0 0 0 11:03:57 4 0 978372 505464 80856 3776280 0 0 162 89 4563 2254 99 1 0 0 0 11:04:07 4 0 978372 711856 80904 3776660 0 0 39 375 4529 2184 99 1 0 0 0 11:04:17 4 0 978372 712272 81088 3777092 0 0 53 71 4527 2205 99 1 0 0 0 11:04:27 4 0 978372 713636 81128 3777476 0 0 38 31 4497 2216 99 1 0 0 0 11:04:37 6 0 978372 671024 81172 3777988 0 0 51 26 4501 2203 99 1 0 0 0 11:04:47 ^C
What do we see?
Disk I/O jumped way up, see bi and bo
under io for blocks in and blocks out of storage.
That caused a number of processes to become blocked waiting
for I/O, see b under procs.
Notice that the total number of active processes,
those in the run queue plus those blocked or the sum of
the first two columns, is much higher during that period.
The blocked processes are forming a bottleneck.
Notice how cache memory use increased as the web server
processes read everything under /var/www/htdocs.
Some free (really meaning "unused so far") and
buffer memory was repurposed.
By the way, something looks wrong here at first.
The wa column under cpu
reports the percentage of time the CPU cores
are in wait state, waiting for I/O.
With 10 or more processes blocked waiting for I/O,
it seems like that should be non-zero!
But the BOINC processes can still run, the CPU cores
are still over 89% busy running user processes (us),
spending 5-11% of their time doing the system tasks
(sy) of file system I/O.
Here's what I did to cause this:
Just after 11:01:57 I started a script that ran 10 parallel
wget commands to recursively read an entire
web site.
Those wget processes were started in the
background so the script finished immediately.
Then just after 11:03:17 I used pkill to
terminate all running wget processes.
The number of active processes goes back to just 4 BOINC
compute jobs.
The disk I/O doesn't finish flushing out for a while,
I resisted the temptation to run the sync command.
Localize I/O Activity with iostat
Without knowing the backstory, all we can tell is that some new processes did a lot of disk I/O making everything sluggish as processes blocked waiting on I/O.
Let's use the iostat command to locate the
disk I/O on a file system as I cause the same problem again.
As with vmstat, ignore the first block.
The trouble starts just after 11:19:26 and is terminated
just after 11:20:26
Linux 4.0.4 (localhost) _x86_64_ (4 CPU)
11:19:06 AM
avg-cpu: %user %nice %system %iowait %steal %idle
8.72 87.05 1.44 0.08 0.00 2.71
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 3.87 32.31 64.85 30882019 61982341
sda1 0.03 0.06 0.10 60554 95075
sda2 0.00 0.00 0.00 36 0
sda5 0.02 0.06 1.84 58943 1756320
sda6 3.82 32.17 62.91 30743058 60130930
sdc 13.97 57.28 818.09 54744753 781901600
sdc1 13.90 57.27 818.09 54739401 781901584
sdb 83.45 335.55 331.34 320709544 316680592
sdb1 83.45 335.55 331.34 320704696 316680576
sdd 0.03 0.29 0.00 279642 40
sdd1 0.03 0.29 0.00 278506 24
loop0 0.00 0.00 0.00 2340 0
11:19:16 AM
avg-cpu: %user %nice %system %iowait %steal %idle
2.67 96.33 1.00 0.00 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 2.20 0.80 12.40 8 124
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 2.20 0.80 12.40 8 124
sdc 1.80 38.80 39.20 388 392
sdc1 1.80 38.80 39.20 388 392
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
11:19:26 AM
avg-cpu: %user %nice %system %iowait %steal %idle
4.33 94.25 1.43 0.00 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 6.50 54.00 24.80 540 248
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 6.50 54.00 24.80 540 248
sdc 6.80 39.20 111.60 392 1116
sdc1 6.80 39.20 111.60 392 1116
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
trouble starts about 11:19:28
11:19:36 AM
avg-cpu: %user %nice %system %iowait %steal %idle
10.58 79.97 9.45 0.00 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 91.20 29.20 16531.60 292 165316
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 91.20 29.20 16531.60 292 165316
sdc 122.20 10690.80 64.00 106908 640
sdc1 122.20 10690.80 64.00 106908 640
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
11:19:46 AM
avg-cpu: %user %nice %system %iowait %steal %idle
13.29 82.08 4.60 0.02 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 61.10 36.40 55806.80 364 558068
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 61.10 36.40 55806.80 364 558068
sdc 54.70 3870.40 35.60 38704 356
sdc1 54.70 3870.40 35.60 38704 356
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
11:19:56 AM
avg-cpu: %user %nice %system %iowait %steal %idle
10.65 82.57 6.78 0.00 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 97.30 9.60 64032.00 96 640320
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 97.30 9.60 64032.00 96 640320
sdc 74.40 4716.80 28.00 47168 280
sdc1 74.40 4716.80 28.00 47168 280
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
11:20:06 AM
avg-cpu: %user %nice %system %iowait %steal %idle
13.78 76.16 10.06 0.00 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 121.70 33.20 80468.80 332 804688
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 121.70 33.20 80468.80 332 804688
sdc 107.00 5320.40 11.60 53204 116
sdc1 107.00 5320.40 11.60 53204 116
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
11:20:16 AM
avg-cpu: %user %nice %system %iowait %steal %idle
17.75 70.85 11.38 0.03 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 180.40 0.00 76016.40 0 760164
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.10 0.00 0.40 0 4
sda6 180.30 0.00 76016.00 0 760160
sdc 124.90 5526.80 14.00 55268 140
sdc1 124.90 5526.80 14.00 55268 140
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
about 11:20:20: pkill wget
11:20:26 AM
avg-cpu: %user %nice %system %iowait %steal %idle
6.70 88.45 4.85 0.00 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 87.40 3.60 50902.00 36 509020
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.10 0.00 0.40 0 4
sda6 87.30 3.60 50901.60 36 509016
sdc 26.10 2313.60 20.80 23136 208
sdc1 26.10 2313.60 20.80 23136 208
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
11:20:36 AM
avg-cpu: %user %nice %system %iowait %steal %idle
2.48 96.47 1.05 0.00 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 5.80 0.00 8584.00 0 85840
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 5.80 0.00 8584.00 0 85840
sdc 4.20 39.60 31.60 396 316
sdc1 4.20 39.60 31.60 396 316
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
11:20:46 AM
avg-cpu: %user %nice %system %iowait %steal %idle
3.00 96.10 0.87 0.00 0.00 0.02
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.00 0.00 0.00 0 0
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 0.00 0.00 0.00 0 0
sdc 4.50 38.40 28.00 384 280
sdc1 4.20 38.40 28.00 384 280
sdb 0.00 0.00 0.00 0 0
sdb1 0.00 0.00 0.00 0 0
sdd 0.00 0.00 0.00 0 0
sdd1 0.00 0.00 0.00 0 0
loop0 0.00 0.00 0.00 0 0
Now we can see that the surge in activity is reading from
/dev/sdc1 and writing to /dev/sda6.
We don't know what is causing the problem, but we can see
how I/O is balanced across storage.
Or in this case, not balanced.
As for the backstory,
/var/www is mounted on /dev/sdc1 and
wget is writing those downloaded copies into
/var/tmp, mounted on /dev/sda6.
Attribute I/O Activity with iotop
So far vmstat told us we have a problem
and iostat told us where it is.
But what is causing the problem?
Use iotop, which must run as root
# iotop -o Total DISK READ : 3.02 M/s | Total DISK WRITE : 53.76 M/s Actual DISK READ: 3.02 M/s | Actual DISK WRITE: 57.70 M/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 22752 be/4 root 814.59 B/s 0.00 B/s 0.00 % 98.61 % [kworker/u12:2] 22852 be/4 cromwell 0.00 B/s 5.41 M/s 0.00 % 92.42 % wget -l 2~Index.html 22864 be/4 cromwell 0.00 B/s 5.42 M/s 0.00 % 91.68 % wget -l 2~Index.html 22846 be/4 cromwell 0.00 B/s 5.45 M/s 0.00 % 88.81 % wget -l 2~Index.html 22855 be/4 cromwell 0.00 B/s 5.43 M/s 0.00 % 87.11 % wget -l 2~Index.html 22858 be/4 cromwell 0.00 B/s 5.41 M/s 0.00 % 86.42 % wget -l 2~Index.html 22870 be/4 cromwell 0.00 B/s 5.43 M/s 0.00 % 85.99 % wget -l 2~Index.html 22867 be/4 cromwell 0.00 B/s 5.43 M/s 0.00 % 85.69 % wget -l 2~Index.html 22861 be/4 cromwell 0.00 B/s 5.41 M/s 0.00 % 84.28 % wget -l 2~Index.html 22843 be/4 cromwell 0.00 B/s 5.03 M/s 0.00 % 60.25 % wget -l 2~Index.html 22849 be/4 cromwell 0.00 B/s 4.66 M/s 0.00 % 57.70 % wget -l 2~Index.html 373 be/3 root 0.00 B/s 495.59 K/s 0.00 % 8.59 % [jbd2/sda6-8] 22873 be/4 apache 414.06 K/s 8.35 K/s 0.00 % 7.86 % httpd -DFOREGROUND 22876 be/4 apache 62.84 K/s 11.14 K/s 0.00 % 7.10 % httpd -DFOREGROUND 22730 be/4 apache 100.63 K/s 15.51 K/s 0.00 % 6.92 % httpd -DFOREGROUND 22733 be/4 apache 1756.85 K/s 7.56 K/s 0.00 % 6.32 % httpd -DFOREGROUND 22874 be/4 apache 258.14 K/s 12.73 K/s 0.00 % 6.07 % httpd -DFOREGROUND 22732 be/4 apache 21.88 K/s 10.34 K/s 0.00 % 5.93 % httpd -DFOREGROUND 22729 be/4 apache 106.99 K/s 7.16 K/s 0.00 % 5.04 % httpd -DFOREGROUND 22877 be/4 apache 113.36 K/s 8.75 K/s 0.00 % 4.86 % httpd -DFOREGROUND 22872 be/4 apache 132.05 K/s 11.14 K/s 0.00 % 3.39 % httpd -DFOREGROUND
There is the problem.
All those wget processes writing and
httpd processes reading web pages and
writing to the log.
Know the Little Tools
Know the dd command, the
/dev/zero and
/dev/null devices,
and the nc network tool.
They provide minimal-cost endpoints for disk and network
I/O tests.
For example, to test disk write speed with a 1 GB tast:
$ dd if=/dev/zero of=/path/to/tested/fs bs=1024k count=1024
Or disk read speed:
$ dd if=/path/to/tested/fs of=/dev/zero bs=1024k count=1024
To verify that it's nearly zero overhead, read a gigabyte of zeros from one pseudo device and discard them into the other. This should finish in well under a second, even on a Raspberry Pi.
$ dd if=/dev/zero of=/dev/null bs=1024k count=1024
To test TCP,
use nc to establish a listening TCP service
on one host, writing its output to /dev/null.
Then from the other host use dd to read 1 GB
of zeros out of /dev/zero and send it through
nc and a TCP connection to the far end.
To test TCP, do the above dd reads and writes,
except use an NFS mounted area of the file system.
Digging Deeper
SystemTap
has a simple command line interface and scripting language
for monitoring and analyzing operating system activity.
It collects the same information you can get through
top, ps, netstat, and
iostat, but it adds further filtering and analysis.
Valgrind helps application developers profile their code and detect memory management errors.
Tuning Oracle
Long ago, you needed lots of added swap area and a dedicated disk device for Oracle. That is no longer the case. Put your database on a modern file system and have enough RAM for the job to fit into memory. Here's how a contact at Oracle answered the questions:
Modern versions of Oracle RDBMS either sit on top of "normal, modern" filesystems (ZFS, XFS or Btrfs on Linux) and use some of their functionality (for example copy-on-write snapshots), or you can also use Automatic Storage Management (usually just referred to as ASM) which makes all of that management somewhat opaque to the DBA. All of the things that the Oracle kernel used to do is pretty common place in today's filesystems and storage systems for Linux and Solaris (logical volume management, striping, parity, snapshotting, replication, non-blocking backup, etc).
As for swap, again, on "modern" machines, it's really not supposed to be used so much for a database workload. The SGA (shared global area) on a busy machine, with a large buffer pool can use quite a bit of memory, and thus back in the days of 32-bit addressing, or 64-bit but 4-8GB of RAM considered being "large", swap could help. However, the rule of thumb on commodity machines where you can install 10s of gigabytes of RAM, or even terabytes (in Sparc Supercluster or Exadata), is that if you've hit swap, you lose. The working set really should be fitting into RAM.
Tuning Internet-Facing Web Servers
On a server accepting many simultaneous connections,
enable the recycling and fast reuse of TCP TIME_WAIT sockets
with tcp_tw_recycle and tcp_tw_reuse.
You might want to decrease the time the server is
willing to wait in the FIN_WAIT_2 state, freeing memory
for new connections.
It defaults to 60 seconds, you might cut that in half
with tcp_fin_timeout.
But monitor carefully when experimenting with this value.
If the server is heavily loaded, especially when clients
have high latency, the number of half-open TCP connections
can climb.
Increase tcp_max_syn_backlog from its default
to at least 4096.
### /etc/sysctl.d/02-netIO.conf ### Kernel settings for TCP # enable recycling and fast reuse of TCP TIME_WAIT sockets net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1 # decrease TCP FIN_WAIT timeout net.ipv4.tcp_fin_timeout = 30 # decrease TCP keepalive from 2 hours to 30 minutes net.ipv4.tcp_keepalinve_time = 1800 # increase TCP SYN backlog to 8192 net.ipv4.tcp_max_syn_backlog = 8192
And finally...
This page has shown you how to make a measurement. But you must be careful to collect and analyze that data carefully.