
Bob's Blog
How to Automate Thousands of Changes Across Thousands of Files
I found that I had 1,441 files
containing 1,651 instances of a pattern that needed
to be changed.
Specifically,
http://schema.org
need to be changed to
https://schema.org
on all those pages, sometimes in multiple places.
After solving this problem I'll explain how it arose
in the first place,
which involves explaining what schema.org and
semantic mark-up is all about.
That isn't important,
or at least it's not my point —
I'm trying to show you how to solve the underlying problem.
The solution is easy, and fast.
That is, if you know how to use the fundamental
commands
find
and
grep
and
sed,
and
how to use Bash shell syntax to turn your command prompt
into a programming environment.
Let's see how to solve this problem!
How Big Was My Problem?
Let's see how many web pages I have for the multiple sites
this server hosts.
Let's find the list of files named *html
and count how many lines (and words, and characters)
that is.
Or, just how many lines and thus files:
$ find /var/www/htdocs* -name '*.html' | wc 2413 2413 113132 $ find /var/www/htdocs* -name '*.html' | wc -l 2413
Wow, 2,413 web pages! How many of them contain the string that must be changed?
$ grep -l http://schema.org $( find /var/www/htdocs* -name '*.html' ) | wc -l 1444
$( ... )
is command substitution.
The command within there runs first,
and it's replaced by its output,
the list of file names.
grep -l
returns just the list of file names
containing the string.
Without the -l
the output would be 1,444 lines,
each containing the file name, a colon, and the matching line.
But in this case we only want to count the file names.
wc tells us how long that list is.
1,444 files that need fixed.
Some files may need multiple fixes. Let's see how many lines need fixing among all those files.
$ grep http://schema.org $( find /var/www/htdocs* -name '*.html' ) | wc -l 1651
1,651 lines need to be fixed within 1,444 files.
Be careful!
Start by making a backup
so you can restore order
after any logic or syntax blunders.
With my web content in subdirectories
htdocs-cromwell-intl.com/,
htdocs-toilet-guru.com/,
and so on, under
/var/www/:
$ cd /var/www $ tar cf ~/web-backup.tar ./htdocs* $ ls -l ~/web-backup.tar -rw-rw-r-- 1 cromwell cromwell 4885606400 Jul 26 18:32 /home/cromwell/web-backup.tar
That took almost 14 minutes, while planning what to do took just a few minutes and running the code took a few seconds. Invest the time in making a backup.
Let's Solve The Problem!
Start by thinking about what we need to do:
-
Start by getting a list of files
that need to be changed.
-
They will be named
*.html. -
They contain the string
http://schema.org.
-
They will be named
-
For each of them,
modify their content changing
http://schema.orgtohttps://schema.org. Note that we do not want to change every instance ofhttp://tohttps://. Even worse yet would be changing everyhttptohttpsbecause that would lead to broken URLs startinghttpss://! -
The
sedcommand is usually applied to data streams, its name is short for "stream editor". However, its-ioption tells it to edit a file in place.
So, as a pseudocode sketch:
list of files needing fixed = name is "*.html" and contains "http://schema.org"
for (list of files needing fixed) {
change all instances of "http://schema.org" to "https://schema.org"
}
We can combine finding the list of files needing fixed with the loop control:
for (list of files named "*.html" and containing "http://schema.org") {
change all instances of "http://schema.org" to "https://schema.org"
}
Creating and Running the Code
So, how can we come up with a list of files
named *.html
which contain that string?
We can use grep -l to get a list of files
containing a string,
but we need to give it the string plus the list of all
files to search.
That's a job for command substitution!
This would give us a list of
all files named *.html.
The single quotes tell the shell not to try to expand
the * wild card in the current directory,
give that literal string to the find command.
$ find /var/www/htdocs* -name '*.html'
[... hundreds to thousands of lines of output appear ...]
We know that we could get a list of files containing a string with something like this:
$ grep -l http://schema.org file1.html file2.html file3.html
[... zero to three lines of output appear ...]
So, we put command substitution to work —
use find to first get the list of all files,
then have grep search them.
$ grep -l http://schema.org $( find /var/www/htdocs* -name '*.html' )
[... hundreds to thousands of lines of output appear ...]
There's our list of files to be fixed.
Now we need to loop over that list,
making a change in each of them.
First, remember the for loop syntax.
Let's say we're in a directory with three files
named *.html:
$ for f in *.html > do > echo "Details of $f:" > ls -l $f > done Details of alpha.html: -rw-r--r-- 1 cromwell cromwell 1072 Apr 28 2024 alpha.html Details of bravo.html: -rw-rw-r-- 1 cromwell cromwell 103095 Nov 17 2023 bravo.html Details of charlie.html: -rw-rw-r-- 1 cromwell cromwell 43241 Jul 5 2023 charlie.html
So, instead of explicitly typing all the file names,
we let command substitution do the work.
Yes, this is an example of
nested command substitution!
The innermost one uses find to get the list
of all *.html files,
and the one wrapped around that uses grep
to pare that down to just those files containing the string.
Then, we use sed in the loop
to make the change for each one.
The pattern we're looking for, and its replacement,
both contain "/".
We usually use that to delimit the pattern and replacement
in sed but in this case we must use
a different character.
To be cautious,
I will first run this in a way that only modifies one file.
The command substitution with find
and grep
aren't needed,
but the point is that I want to test the logic on a single
file before turning it loose on multiple sites.
Let's make sure I'm testing on a file that needs
to be fixed:
$ grep schema.org /var/www/htdocs-cromwell-intl.com/Index.html
<article itemscope itemtype="http://schema.org/Article">
Yes, that file needs to be fixed.
I will run the code with
find searching only for that one file.
$ cp /var/www/htdocs-cromwell-intl.com/Index.html /tmp $ for f in $( grep -l http://schema.org $( find /var/www/htdocs-cromwell-intl.com/Index.html -name '*.html' ) ) > do > sed -i 's@http://schema.org@https://schema.org@g' $f > done $ diff /tmp/Index.html /var/www/htdocs-cromwell-intl.com/Index.html 13c13 < <article itemscope itemtype="http://schema.org/Article"> --- < <article itemscope itemtype="https://schema.org/Article">
That looks good!
Now let's fix all the files.
I will run this within time to see how long
it takes:
$ time for f in $( grep -l http://schema.org $( find /var/www/htdocs* -name '*.html' ) ) > do > sed -i 's@http://schema.org@https://schema.org@g' $f > done real 0m5.770s user 0m1.809s sys 0m2.594s
Problem solved in just 5.77 seconds!
2.594 seconds for the kernel to do all the disk I/O, 1.809 seconds of processing, and 5.770 seconds of wall-clock time.
These are the results on my laptop with its not SATA-connected mechanical disk. There were 2,413 HTML files within 4,886 MB of web content. The needed 1,651 changes were made in just 5.77 seconds! As I mentioned, the crucial step of making the backup took almost 14 minutes, and my planning and test run took just a few minutes while the backup was being created. The entire project took less than 20 minutes. How many weeks would this have required if you set the unpaid intern to work making the 1,651 changes, and how many erroneous changes would have been inserted?
Uploading all those changed files to my server
with rsync
took almost 24 seconds,
given the 3.95 Mbps bandwidth
available at the coffee shop
where I'm writing this.
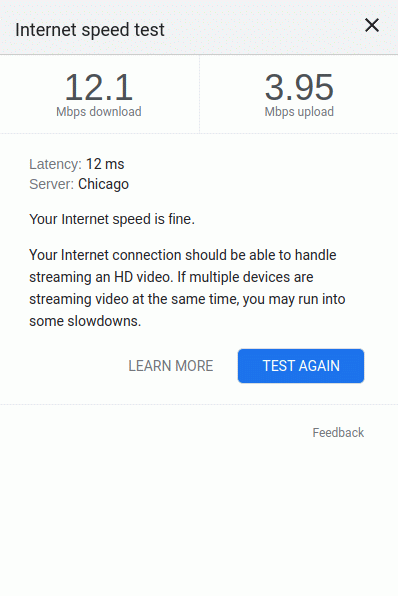
Excellent! But...
What is schema.org?
How Did This Become a Problem?
The semantic web project aims to make web pages more meaningful to search engines so the pages can be more easily discovered and used by people. A big part of that has been structured data mark-up within web pages. That's information that can be used by search engines or other automated analysis but which isn't visible to the person viewing the page with a web browser.
Let's say you own a bar where there are daily food and drink specials and live music on the weekends. You would like for a vague search for "bar" or "music" to lead to a search engine results page including "rich snippets" for your site, a summary of those specials and events right there in the search results. Maybe that sends a customer to your business immediately. Or at least it encourages them to view your page instead of your competitors' pages. Art museums could also benefit from this, with terse details about days and hours of operation, current exhibits, and other useful information right there in the search results.
Here's an example of Google selecting and organizing information from one or more pages on a site, generating content not found in that literal form on the original pages:
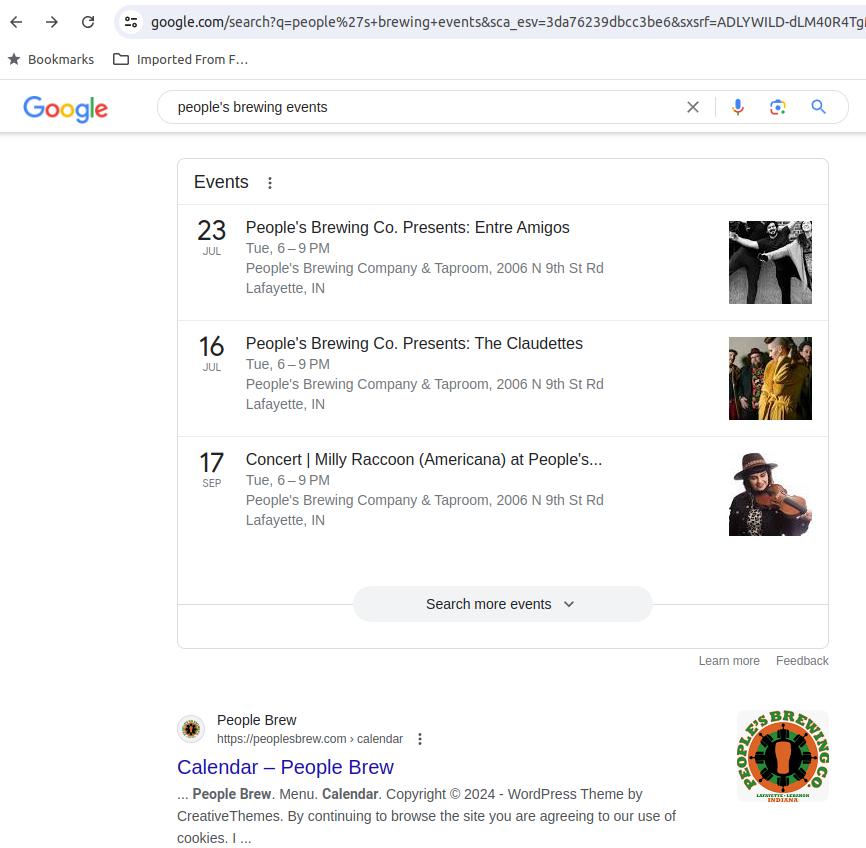
All this became of interest in the early 2010s. The schema.org web site appeared in 2011. It is the reference for the microdata form of structured data to embed within web pages. There is also a RDF syntax, and for curly-brace lovers you can do it in JSON.
Because of the nature of the content, the travel pages on cromwell-intl.com have much more semantic mark-up than the technical pages. Here's an example of schema.org markup within /travel/japan/hakodate/ofune-site/, with the semantic microdata highlighted.
<!DOCTYPE html>
<html lang="en" xml:lang="en">
<head>
<meta charset="UTF-8">
<title>Ōfune Site — Prehistory in Hokkaidō</title>
<meta name="description" content="Jōmon culture settlement at Ōfune Site inhabited 3500–2000 BCE, visiting by bus and a short walk.">
<meta name="twitter:image" content="https://cromwell-intl.com/travel/japan/hakodate/ofune-site/pictures/ofune-site-20240503-124039.jpg">
<meta property="og:image" content="https://cromwell-intl.com/travel/japan/hakodate/ofune-site/pictures/ofune-site-20240503-124039.jpg">
</head>
<body>
<article itemscope itemtype="https://schema.org/Article" class="container-fluid">
<meta itemprop="about" content="travel">
<meta itemprop="about" content="prehistory">
<meta itemprop="about" content="Jōmon culture">
<meta itemprop="about" content="Ōfune Site">
<meta itemprop="about" content="Japan">
<header>
<div>
<img src="pictures/walk-20240503-132247-4000x823-0x1092.jpg"
alt="View through tunnel walking along the coast road from the Ōfune Site to the Kakinoshima Site.">
</div>
<h1> Ōfune Site </h1>
</header>
<div itemscope itemtype="https://schema.org/Place">
<meta itemprop="name" content="Ōfune Site">
<meta itemprop="containedInPlace" content="Hakodate">
<meta itemprop="containedInPlace" content="Hokkaidō">
<meta itemprop="containedInPlace" content="Japan">
<meta itemprop="containedInPlace" content="Asia">
<meta itemprop="containsPlace" content="dwellings">
<meta itemprop="containsPlace" content="earthworks">
<meta itemprop="containsPlace" content="burial pits">
<meta itemprop="containsPlace" content="coast road">
<span itemprop="geo" itemscope itemtype="https://schema.org/GeoCoordinates">
<meta itemprop="latitude" content="41.957778">
<meta itemprop="longitude" content="140.925278">
</span>
[... content of page ...]
</div> <!-- schema ... Place -->
<?php include($_SERVER['DOCUMENT_ROOT'].'/ssi/footer.html'); ?>
</article>
</body>
</html>
The promise was that semantic mark-up would make your site much more attractive in search engine results. I'm not selling anything, but I have a variety of ads on my pages. Supposedly web traffic and thus ad revenue would surge with the addition of the microdata.
In 2011 I had way fewer web pages. I was teaching quite a bit, leading to evenings in hotels without much to do. With some organized copy and paste, it was easy to get the basic content into the pages. And, most of them had far simpler metadata than the travel example above.
After that, I continued as I was already doing, copying an existing page to start a brand-new one. Then I might need to update the metadata. If I created a new page about Linux, or networking, or cybersecurity, the existing metadata was very close, if not precisely what I needed.
It has been travel pages that need a little more attention.
Modify the about and Place
that the page describes,
modify the containedInPlace
and containsPlace fields,
and use Google Maps or Wikipedia to update the
latitude and longitude fields.
The problem was caused back in the early 2010s by schema.org telling us to use HTTP instead of HTTPS URLs. I eventually noticed that HTTPS also works, and changed whatever page I was creating at the time. Then over time, my copy-and-modify model propagated that update to many pages, but only 1,444 out of 2,413, almost 60% of them.
The good news is that this was easy to fix.
So, Would I Use Semantic Markup Today?
No. I don't see any benefit to me, given the nature of my sites. It might help the search engines, but not in a way that provides a clear benefit to me. If I had a client with constantly changing events, like a museum or restaurant or bar or theater or church, I would recommend it. But then someone must constantly modify the metadata.
See comments on Reddit and Quora for discussion. Google has really promoted this type of metadata for some time. However... In some situations Google uses different syntax than what schema.org specifies. And, as I already mentioned, this doesn't seem to have any benefit for my travel and technical pages.
Things became more confusing because people began referring to the Semantic Web concept as "Web 3.0". And then the techbros began using "Web3" to refer to their various cryptocoin pyramid schemes, supposed "A.I.", and other wastes of electricity and cooling. "Web 3.0" seems to have very limited benefit, but at least it isn't accelerating the destruction of the climate the way "Web3" is.
My Goal For This Page
I hope that this gives you an idea of the power of using the command prompt as a programming interface, and impresses you with how you can easily and quickly solve what seems to be an enormous problem.
Updating hundreds of schema.org URLs was the example problem I needed to solve. You could apply this approach to anything.
Next:
10 Billion Passwords, What Does It Mean?
RockYou2024 is a list of 10 billion unique leaked passwords. Let's analyze what that really means.
Latest:
Automating Changes Across Thousands of Files
I needed to change 26,756 lines in 1,564 files — it was fast and easy with a command-line environment.
Previous:
What is "A.I.", or "Artificial Intelligence"?
So-called "A.I." is hype and misunderstanding, here's hoping the next "A.I. Winter" arrives soon.
Books I've Read: "The Origin of Consciousness in the Breakdown of the Bicameral Mind"
According to the author, humans only became truly conscious in the second millennium BCE, and schizophrenia may be a holdover or return to the pre-conscious state.
What's Up With My Social Media Postings?
I have an automated Mastodon identity that posts numerous factoids of widely varying relevance. What's going on?.
Why I Abandoned OpenBSD
OpenBSD is technically OK but I won't be involved with, or appear to support, such a toxic environment.