
Operations Domain
DNSSEC
There are some questions about DNSSEC. There are DNS resource records for public keys (DNSKEY) and digital signatures (RRSIG). With DNSSEC you can believe that a response is correct, including a response that the requested record doesn't exist. This server is in the Google Compute Cloud, Google's DNS service includes DNSSEC:
$ dig @8.8.8.8 cromwell-intl.com ANY ; <<>> DiG 9.11.3-1ubuntu1.9-Ubuntu <<>> @8.8.8.8 cromwell-intl.com ANY ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23210 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 18, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;cromwell-intl.com. IN ANY ;; ANSWER SECTION: cromwell-intl.com. 3599 IN A 35.203.182.32 cromwell-intl.com. 3599 IN RRSIG A 8 2 3600 20191023184932 20191001184932 1336 cromwell-intl.com. kZvoWcuVgaqVQifdA6BWGNgGjeFceDzuXRkJUtJBau10iGvDUPDQlrdK RuM6CMrfpR34YNBFo+SLS7JeJNWcekpoFp/pcdLWsMe8DYPQ68k9Ub1q xVg82QEkIf5gX8wgy1PTqKMfUyZdcj98MSbZfQdO/+9tfVNo5Q8VjqJy VTw= cromwell-intl.com. 21599 IN NS ns-cloud-c1.googledomains.com. cromwell-intl.com. 21599 IN NS ns-cloud-c2.googledomains.com. cromwell-intl.com. 21599 IN NS ns-cloud-c3.googledomains.com. cromwell-intl.com. 21599 IN NS ns-cloud-c4.googledomains.com. cromwell-intl.com. 21599 IN RRSIG NS 8 2 21600 20191023184932 20191001184932 1336 cromwell-intl.com. SN9nldXgN84Kzi/BWUMiG5PWoG3fYdXgN433KOmLelQUzB1FF0XHPFng b0/zCJc8PMxw8VPSaN0EI/6X9p55q5Sz7/takGtqAKLxGSfKoGRd4xFs 0qazkiWKkgP49ueGdQUSUPxTPAHhFMpcfvSAHhlJur/xGbMwQ741wnsG q30= cromwell-intl.com. 21599 IN SOA ns-cloud-c1.googledomains.com. cloud-dns-hostmaster.google.com. 9 21600 3600 259200 300 cromwell-intl.com. 21599 IN RRSIG SOA 8 2 21600 20191023184932 20191001184932 1336 cromwell-intl.com. Xczvq1biZTr9yaBijlCuwvrRzg4u6fSEMh2twfH50+PdswzhMxh01uJK Uur7VaH/WeSE1DQpaM4n13yTZI6YNnBra4xSlYC4vatE5UmEAZ/5oqxb QP4IglU7u/vLaizO8deJKsla0LP4VkdOq1fDpOEpPwVwhur3cCgpAQz6 klI= cromwell-intl.com. 299 IN DNSKEY 256 3 8 AwEAAZhaibf1ewwx+uvJF/LIU0rNbhmtZIVcWnRECDRYzh7CAKn4fMT8 6lEW5QI02wqoHUCdrLjgG60N4A3jm+vLF/+2uhWfOR/zuTEXSPmQd5Aj xYHf/0FSZiBHhI2coXPhgGQ9Mu/a/zRTraE2qDrmTlM3/nzGJ0tQVQFp 41OKs8Tn cromwell-intl.com. 299 IN DNSKEY 257 3 8 AwEAAaJd0s3/TaTnNKSKq4V/DKT00k7oE4s7txW1EicoAsvimyLeWLmX 2Prl44lTu4Mqk3MzGJO7SnWW/ALE/hxKvgXPzTsh+0zpiOEnf5BCl+M/ pdhRIKnGcoyQ1/dyMkEHoX6pa7kgdN13pdqGYRdwZS3UkZjpZB8KC6Ev +++twCkNhb9hIXVdRfOT1xGvonQ5TcP0o3y5t52tX6FudmZ7RhKoGE6Y 6VTbYfVBWiUjic3TTgQADnYiOV3Sgl/K4cOzMfmlmWdxuU2tO3UpF0o9 apKJTwCvc6ESeaE/egUMxyB3ciduqoMKjuD22350mfjfLNWUp1sqYYji awYVPx79sCE= cromwell-intl.com. 299 IN RRSIG DNSKEY 8 2 300 20191023184932 20191001184932 18860 cromwell-intl.com. m9JDLOACSephnNEvMPJYHeIhAFMbmq5o1MV0TwqQ++5OweN0ZAc4zfCo ltXBXdNVf+A4DYtqEJMwWr1S2shJERY15neGKJyeizZlLgLyFbwE5mY+ A3Sb3FCY3c8SmHQhA0sNa+w7C/KZpMJ4ZIugzWOupqDaES+7qBdI+kwp J0k1yF3PmnbbbFgtnhHT+lF7+bIc2EDtbCPSUxJCKyYmlM1Ik0TwxXGZ eGsmCVr71WlcFONdNYYzkp3r3cp6NkAJkkgiTKXpN+27XISgOuGdNTZi HF8a1U4NBwLTcMpyKedbC9GKGXJaPoQXJdPi+csFFvRPVbBJ1RuKeU+Y rvsEhg== cromwell-intl.com. 0 IN NSEC3PARAM 1 0 1 E3770CCDAA2128C5 cromwell-intl.com. 0 IN RRSIG NSEC3PARAM 8 2 0 20191023184932 20191001184932 1336 cromwell-intl.com. lbi/Qs4R8PgjSxrbN9m8NNBiNGCVYnj1tEBtZNoMH6oi507KzAxFAmD2 uwgD3xEeKqElyAYHPOlEjap1RjOG/l6017qjqdw5jBHuV7/f+IXmJC4n kq1y79/crPvhSX0R69uW/PA+J9XFrTr7O0sfmygOWPLYMhH4ECBNqL66 hbQ= cromwell-intl.com. 299 IN CDS 18860 8 2 92F4893D8FC1852873EF1C1E2368DFF63A63D8EB9C28AFE3226B5F12 1A9AC80D cromwell-intl.com. 299 IN RRSIG CDS 8 2 300 20191023184932 20191001184932 18860 cromwell-intl.com. nvH3OwVzuPWk6M6EpL1vC2c7DfBxu1fOhsiEwzH9pcddT9jIzjjliXzU qFc9RHq9HIptlhFTNvAmLCZZSAcsVw/q+WO/B4i+y2n2wV4I2R0+1vid vH7b1lkn0rx/KWbTqBrkJq1HpJLjkvKWdTJaGsanfO7Ne5oTfHvBUTGE wfst4EdCMYUYtJbCEkwGgsBsmtzv64oQvO+JKG4MvzUSN+jvw16Prl5y AF6ziAMkgGLI+02u0IJzIRMnoaJz6vApORXlZ0rMC8+1B0hpCBilNTao Ylg9QkYrqB8fKs8QKJ1xtQ0NadhFwjGPivvMiIM8lspXkQTmkGt0bUBe 5KxGbg== cromwell-intl.com. 3599 IN CAA 128 issue "letsencrypt.org" cromwell-intl.com. 3599 IN RRSIG CAA 8 2 3600 20191023184932 20191001184932 1336 cromwell-intl.com. lNvXUGJ7f/GNHpxahT2/Q7heM9cD/H555ruz1dbhP7MbCZs03hacqu0H p2SZmIOrq9Hb5IhXIB+TstQFIsemFpZGP2vwuRf6+VeVGlniN8DsRbMy k8BI0c8/r0xcxFoS2JIQvZ+G2/b927bvYEoSgkGSUMIMoa13mBLYrsTZ rSc= cromwell-intl.com. 3593 IN TXT "v=spf1 -all" cromwell-intl.com. 3593 IN RRSIG TXT 8 2 3600 20201210125948 20201118125948 5796 cromwell-intl.com. qI2mc1oxmUcggiQ9y+tPBe8QbtC4TDnQeI9UX+bky1mAIo/SrptNlbVv U62gu6edGxiHyuWU7/3wEN5HRsIUv7WqC/xXWw1c1B6u07HGngzoMSar lMCXqj6oYDxjnlRxgURFgnFMCSNztUpe62DCWCqhepvFz87Q/b9OTSGU 4OE= cromwell-intl.com. 3593 IN MX 0 . cromwell-intl.com. 3593 IN RRSIG MX 8 2 3600 20201210125948 20201118125948 5796 cromwell-intl.com. RnjXh2rSESCveU15X8AOYPcFxmResrJv1qdo52VnrnjzegebxX2VDvCr OwBXBG3ebTAFEOIdL09Skm8N27NgMjB9H0Z2HZ9BXdYMMUlTUesDJs6P IAVgCIhqFGccu3kfVzogsMBxEm+LWXap3wpgp/J0Qez2umfThwqxt6rZ mag= ;; Query time: 247 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Fri Oct 04 12:20:50 EDT 2019 ;; MSG SIZE rcvd: 2270
The A record says that the IPv4 address is 35.203.182.32.
The RRSIG A record is a Signature Resource Record, with a digital signature for that A record. Then the RRSIG NS record validates the NS records, and so on.
ISO 22237 Protection and Availability Classes
Increase as you move toward the more critical core.
- Protection Class 1: Public or semi-public area.
- Protection Class 2: Accessible to all authorized personnel, employees and visitors.
- Protection Class 3: Restricted to specified employees and visitors, those with access to Class 2 only must be accompanied by Class 3 personnel.
- Protection Class 4: Even stricter, need to demonstrate need for access.
Uptime Institute Data Center Site Infrastructure Tier Standard Topology
-
Tier I: Basic Data Center Site Infrastructure
-
Tier II: Redundant Site Infrastructure Capacity Components
-
Tier III: Concurrently Maintainable Site Infrastructure
-
Tier IV: Fault-Tolerant Site Infrastructure
| Feature | Tier I | Tier II | Tier III | Tier IV |
| Active components supporting IT load | N | N+1 | N+1 | 2N or 2N + 1
The point is to always have N after any failure |
| Distribution paths | 1 | 1 | 1 active and 1 alternate |
2 simultaneously active |
| Concurrently maintainable | — | — | Yes | Yes |
| Fault tolerant | — | — | — | Yes |
| Compartmentalization | — | — | — | Yes |
| Continuous cooling | — | — | — | Yes |
Environmental controls
| Temperature thermostat at chiller intake |
min: 18 °C (64.4 °F) |
| max: 27 °C (80.6 °F) | |
| Humidity | min: 40% |
| max: 60% | |
| Raised floor height | at least 24" |
Latent cooling = removing moisture
Sensible cooling = removing heat (can be sensed by thermometer)
Put thermostat at input to chiller.
UPS and Generators
- UPS needs to run long enough for graceful shutdown
- Generator needs to be online before UPS fails
- Generator needs 12 hours of fuel, resupplying as needed within 12 hour windows
- Gas and diesel spoil, so liquid propane is better
I've done work for Cummins, so here we go much further down the rabbit hole than is appropriate. Ignore this when preparing for the test:
- LNG or Liquified Natural Gas is a cryogenic fluid, about 99% methane or CH4. It's good for bus engines, stored in a Dewar tank like a giant Thermos bottle. Good energy density, easy to handle and store.
- CNG or Compressed Natural Gas might be vaporized LNG or maybe compressed pipeline gas, which might be more like 95-96% methane. It's stored at 5,000 PSI, so it needs sturdy tanks: either heavy steel or aluminum internal skin with carbon fiber overwrap, which is expensive.
- Propane is CH3—CH2—CH3 and automotive spec propane is pretty pure. The bottles for grills and heaters are less pure, other hydrocarbons are in the mix. Propane is stored at 30-50 PSI, so the tanks still need periodic hydrostatic testing but it's relatively cheap.
- LP or Liquified Petroleum gas is a mix of propane and others hydrocarbons, mostly heavier.
- Gas engines (meaning LNG/CNG/propane, not gasoline) take longer than diesel to get to full rated power, so the data center UPS will have to support full load a little longer as the genset spins up. Maybe something like magnetically levitated flywheels spinning generators.
Time / Frequency Concepts
- Goal is usually "five nines", 99.999%, under six minutes per year
- MAD = Maximum Allowable Downtime — Cannot be down longer than this. (or company fails, perhaps), aka MTD = Maximum Tolerable Downtime, maybe MTPD or Maximum Tolerable Period of Disruption
- RTO = Recovery Time Objective — We want to be back up this soon. (significantly faster than MAD)
- MTTR = Mean Time To Recovery — On average, recovery takes this long.
- RPO = Recovery Point Objective — We can afford to lose this much.
- MTBF = Mean Time Between Failures — On average, it fails this often.
- RSL = Recovery Service Level — During disaster and following recovery, we need at least this much.
"About twice a year we have a major storage failure. We make backups nightly starting at 1 AM. Our goal is to get data restored within 1 hour. If we went 8 hours without data, our company would financially suffer. Over the past year, our data recovery process has averaged 41 minutes. While recovering one file system, we need at least 80% normal performance on the other unaffected file systems." For that story:
- MTBF = 6 months
- RPO = Within the past 24 hours
- RTO = 1 hour
- MAD = 8 hours
- MTTR = 41 minutes
- RSL = 80% or 0.8
Maintenance Mode
Used when updating or reconfiguring the host, where the hypervisor runs.
- Customer access (starting new VMs) is blocked
- Live-migrate running VMs to other hosts
- Disable alerts
- Leave logging enabled
- Administrator access only, possibly restricted to physical console
- Follow vendor guidance and best practices
Clustered Hosts and Resource Sharing
- Reservations guarantee a minimum amount of resources to a specified VM
- Limits guarantee a maximum amount of resources to a specified VM
- Shares provision remaining resources left when there is resource contention. Allocate reservations first, then shares (prioritized, percentage-based) for the remaining resources to the other members.
"Everyone gets a sandwich, and Elite customers get 2. No one can have more than 4 sandwiches. After everyone gets their promised sandwiches, we'll fairly distribute what's left over."
- Reservations = 1 or 2, depending on customer
- Limits = 4
- Shares = Fair leftover distribution
SDN Orchestration
The below is far deeper than you need to know for the test, but cloud services like Google Cloud and AWS and Microsoft Azure and so on must use SDN. Here's what the AWS dashboard shows you of the orchestration parts of a multi-VM deployment with network orchestration. Amazon calls this "CloudFormation". Here we're starting multiple:
- Database instances
- Security groups (firewall rulesets)
- Load balancers
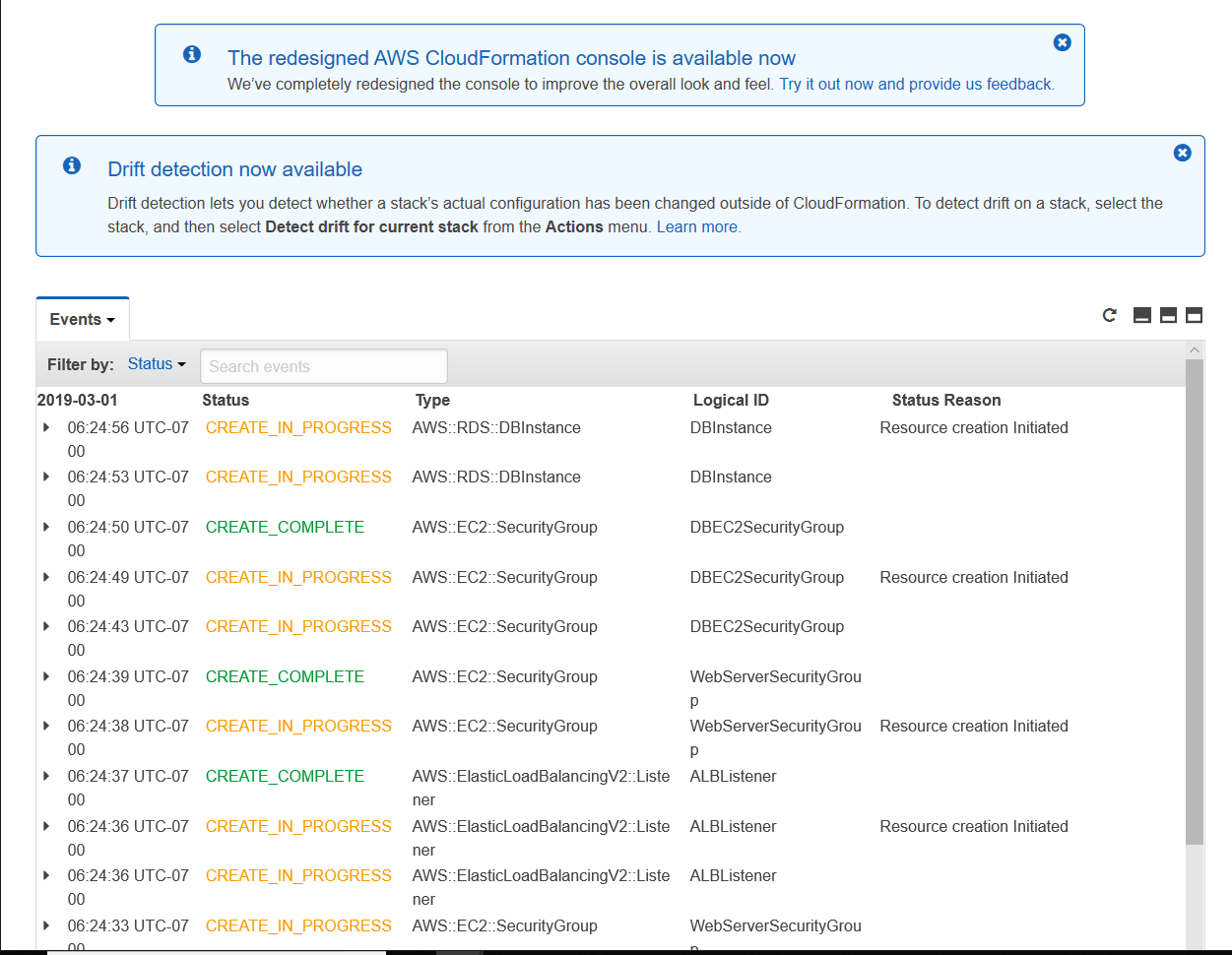
Many thanks to Carter Elmore for the screenshot!